

Macro | 🪫 Stati della computazione/2 🪫
Macro | 🪫 Stati della computazione/2 🪫
Sull'ipertrofia energetica della computazione contemporanea.

“Stati della computazione” è una serie di articoli sulle tecnologie del calcolo contemporanee.
Viene pubblicata su questa newsletter e su Appunti di Stefano Feltri.
Come da sottotitolo, oggi parliamo di costi energetici ma prima…
È finalmente online il video (in inglese) della conferenza organizzata dall’Università Bocconi a cui ho partecipato a fine settembre.
Il tema, come da titolo, era la posizione della UE nella “guerra dei chip”. Tutti gli interventi sono stati interessanti ma vi consiglio quello di Daniel Gross (minuto 45) – economista e direttore dell’Institute for European Policymaking della Bocconi – che solleva una questione sulla dicotomia tra gli investimenti nella produzione di hardware e quelli nella ricerca di software molto rilevante per gli argomenti di questa serie (ci torneremo nel quarto episodio di “Stati della computazione”).
Iniziamo.

Nella precedente puntata ho scritto che il primo a parlare di miniaturizzazione dei chip fu, nel 1965, il futuro co-fondatore di Intel Gordon Moore. In realtà non è del tutto accurato.
In merito esistono intuizioni ancora precedenti, inclusa una nientemeno che di Richard Feynman, uno dei più geniali fisici del Novecento. Il 29 dicembre 1959, durante l’annuale incontro dell’American Physical Society presso il California Institute of Technology, Feynman tenne un discorso seminale per lo sviluppo delle nanotecnologie e della microelettronica. Sarebbe passato alla Storia con il titolo di “There’s plenty of room at the bottom” (“C’è un sacco di spazio laggiù in fondo”).
Feynman sosteneva che per aumentare la potenza di calcolo dei computer, non si doveva guardare verso l’alto – cioè verso un aumento delle dimensioni degli strumenti informatici – bensì in basso – “laggiù in fondo” – verso la miniaturizzazione dei componenti.
Nel ‘59 i computer erano attrezzature che occupavano intere stanze e consumavano quantità di energia enormi. Si racconta che ogni volta che l’ENIAC – il primo calcolatore di tipo “moderno” – veniva messo in funzione le luci di un quartiere di Philadelphia si affievolissero.
Le considerazioni di Feynman erano perciò non solo opportune ma tempestive specie se consideriamo che, proprio nel 1959, venne assemblato il primo circuito integrato monolitico (in altre parole: il primo chip). Ecco un passaggio:
Perché non possiamo renderli (i computer, ndR) molto piccoli, con piccoli fili, piccoli elementi – e per piccoli intendo davvero piccoli? Ad esempio, i fili dovrebbero avere un diametro di 10 o 100 atomi, e i circuiti dovrebbero essere larghi qualche migliaio di angstrom.
Tutti coloro che hanno analizzato la teoria logica dei computer sono giunti alla conclusione che le potenzialità dei computer sono molto interessanti – se potessero essere resi più complessi di diversi ordini di grandezza.
Se avessero milioni di volte più elementi, potrebbero fare valutazioni. Avrebbero il tempo di calcolare qual è il modo migliore per eseguire il calcolo che stanno per fare. Potrebbero scegliere il metodo di analisi che, data la loro esperienza, ritengono migliore.
[…]
Se volessimo costruire un computer che avesse tutte queste straordinarie capacità qualitative, dovremmo probabilmente farlo delle dimensioni del Pentagono. Questo presenta diversi svantaggi. Innanzitutto, richiederebbe troppo materiale; non ci sarebbe abbastanza germanio nel mondo per tutti i transistor da inserire in questo enorme aggeggio.
C'è anche il problema della generazione di calore e del consumo di energia […]. Ma un problema ancora più pratico è che il computer sarebbe limitato a una certa velocità. A causa delle sue grandi dimensioni, ci vorrebbe un tempo finito per trasmettere le informazioni da un punto all'altro.
Detto che alcuni elementi contenuti nei computer attuali sono persino più piccoli di quelli immaginati da Feynman e che, negli anni Sessanta, si smise di produrre microchip in germanio, e si cominciò a farli di silicio, proprio per una questione di abbondanza di questo elemento, Feynman parla qui in modo esplicito della relazione tra l’aumento della potenza di calcolo e la possibilità che i computer sviluppino “capacità qualitative” assimilabili all’intelligenza umana. Ovvero ciò che oggi chiamiamo intelligenza artificiale.

Megachip
Feynman sarebbe probabilmente sorpreso nel constatare che, sebbene i transistor abbiano raggiunto dimensioni irrisorie, per far emergere le “straordinarie capacità qualitative” di cui parlava non è sufficiente un Pentagono. Servono svariati Pentagono.
Certo, non si tratta di un singolo computer “delle dimensioni del Pentagono”… ma di milioni di chip specializzati dentro decine di migliaia di cabinet all’interno di migliaia di data center. Le ultime cifre parlano di 11mila data center attivi nel mondo, per una superficie complessiva di circa un miliardo di metri quadrati, equivalenti a 1800 Pentagono o, se preferite, a più di cinque volte l’area del comune di Milano (qui un mio pezzo sul consumo di suolo di queste strutture).
Solo poco più del 20% dei data center ad oggi operativi è dedicato alla computazione per l’addestramento dell’AI ma la domanda di potere computazionale destinata a questo scopo è in grande crescita e, nei prossimi anni, si prevede un’esplosione edilizia nel settore.
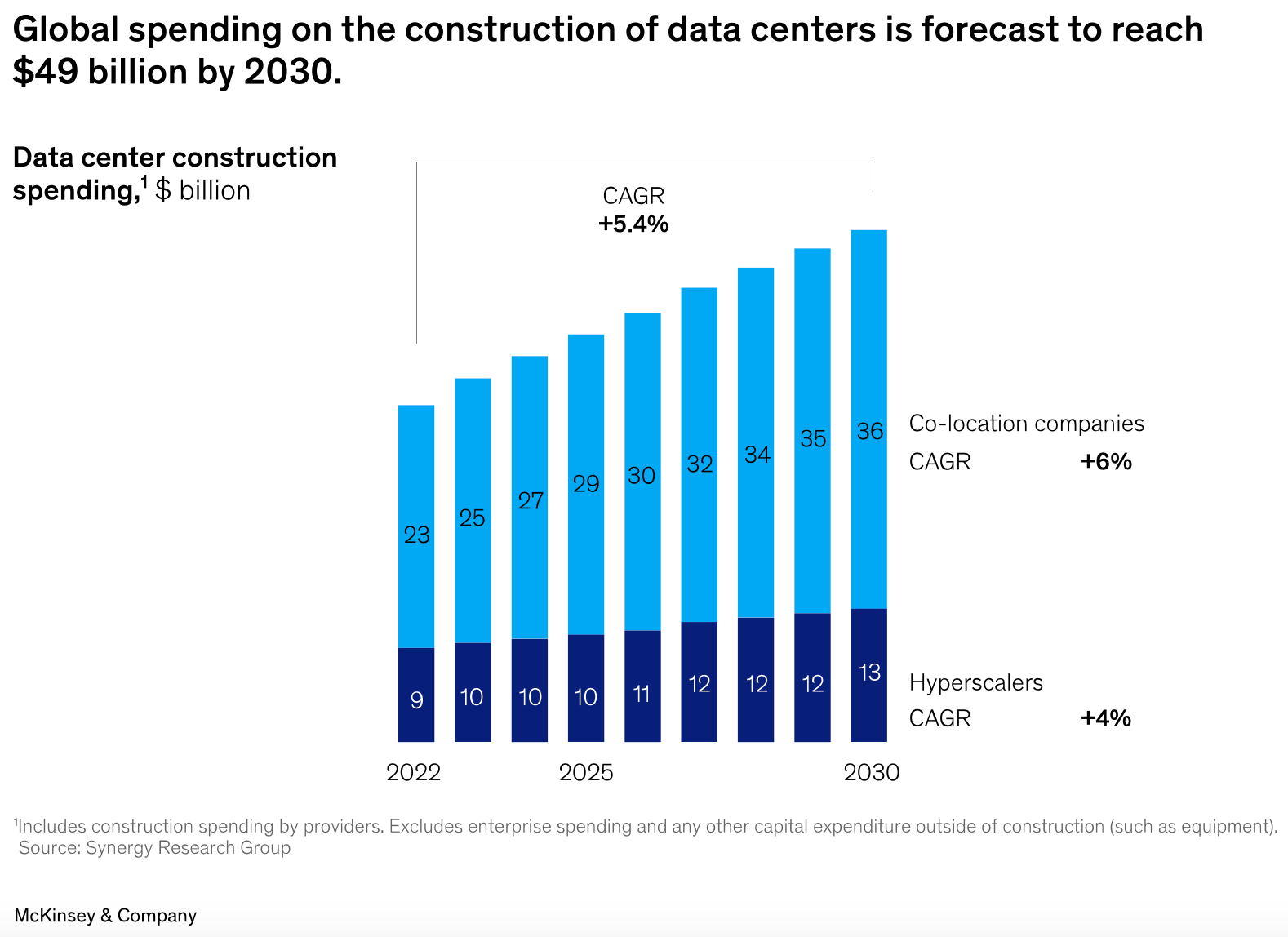
Feynman sarebbe inoltre sorpreso dal fatto che, anziché continuare a rimpicciolirsi, di recente diversi hardware avanzati hanno cominciato a diventare più grandi. Questo fenomeno ha a che fare con le difficoltà connesse alla miniaturizzazione dei transistor che ho raccontato nella precedente puntata. Il problema è che oggi “laggiù in fondo” (ovvero nelle dimensioni più piccole della materia) non c’è più “un sacco di spazio” per incrementare la capacità di calcolo.
Per questo motivo numerose aziende, inclusa Nvidia, hanno cominciato a progettare processori sempre più grandi, così da aumentare il numero di transistor (e di core) che contengono senza doverli rimpicciolire. Se fino a pochi anni fa la maggioranza dei chip era grande come monete da pochi centesimi, oggi sono normali mega-chip grandi quanto piatti da portata.
Uno dei competitor in prospettiva più promettenti di Nvidia è un’azienda di San Diego relativamente giovane (è stata fondata nel 2015). Si chiama Cerebras e i suoi chip più grandi – i WSE-3 – sono grandi come un intero wafer, il termine tecnico con cui si indicano i dischi di silicio lavorato, da cui normalmente si ricavano decine di chip. Non per caso si parla di Wafer-scale integration.

L’idea di Cerebras è di fornire, su un singolo enorme chip, un sistema computativo pari alla potenza di numerose GP, in modo da semplificare l’assemblaggio e la programmazione dei cluster di computazione. Ciò è reso possibile dall’enorme quantità di transistor che un WSE racchiude in così tanto spazio: 2,8 triliardi. Anche il prezzo (mai ufficialmente divulgato dall’azienda) si presume extralarge: le voci parlano di 2/3 milioni a pezzo.

Ciò ci riporta al problema dell’accessibilità di questi hardware e al fatto che (al momento) sembriamo essere tornati a un tempo in cui i computer erano strumenti iper-specializzati e costosissimi, gestiti da poche entità che ne affittavano l’utilizzo un tanto all’ora. Esiste anche un’espressione – “big iron” – per indicare quell’epoca che alcuni credevano finita per sempre con l’avvento dei personal computer.
Anche se a ben vedere i super-computer e le grandi infrastrutture della computazione non hanno mai smesso di esistere in parallelo all’informatica di largo consumo, più di un economista ha segnalato come questo sviluppo rischi di tagliare fuori interi paesi dal futuro di tecnologie critiche, con ricadute più ampie sui tassi di disuguaglianza economica tra – e all’interno degli – Stati (su questo torneremo nella prossima puntata, mentre nella quarta ci occuperemo di possibili soluzioni alternative).
Un’ulteriore criticità di questa tendenza – come ben sapeva Feynman – è che maggiore è la dimensione di un circuito e maggiore è la superficie che gli impulsi elettrici devono attraversare per farlo computare. Per questo, e per altri motivi, i mega-chip sono componenti tecnologici che, in assoluto, consumano più energia dei chip “normali” (oltre a richiedere molta più energia per essere prodotti, come racconto nel mio libro). E tuttavia potrebbero comunque essere una soluzione energicamente più efficiente rispetto alle configurazioni attualmente in uso.
Grandi infrastrutture, grandi consumi
Persino più dispendiose ed energivore dei mega-chip sono le attuali infrastrutture per la computazione AI, basate su data center in cui decine di migliaia di GPU ed altre componenti (TPU, DPU, NPU) vengono destinate all’addestramento di un singolo modello linguistico di grandi dimensioni (LLM).
Secondo l’Agenzia Internazionale dell’energia, nel 2022 il consumo di energia dei data center (non soltanto legati all’AI) è stato di 1,6 miliardi di gigajoules, ovvero il 2% del globale.
Le previsioni di crescita dei consumi connessi all’addestramento e all’utilizzo delle AI vanno dalla catastrofica stima secondo cui il processo consumerà il 20% (!) dell’elettricità globale già nel 2030 ad altre, più moderate (e francamente credibili), che prevedono una percentuale intorno al 4,5% (un’aumento del 160% rispetto all’inizio di questo decennio). Che è comunque moltissima energia per una singola applicazione.
Questa crescita non è solo dovuta alla quantità di hardware dispiegata ma alle caratteristiche intrinseche agli algoritmi per l’addestramento dell’AI. I quali comportano un continuo e ripetuto avanti e indietro – dalle memorie ai “cannoni” della computazione e viceversa – di colossali quantità di informazione all’interno dei database più grandi della Storia.
Questo intenso traffico è reso possibile dal movimento di elettroni all’interno di chip che per una ragione (leak indesiderati) o per l’altra (le dimensioni) dissipano sempre più energia sotto forma di calore.
Questa è anche la ragione fisica per cui i computer si scaldano e, tra tutte le tipologie di computer, i server sono quelli che si scaldano di più. Il che rende necessaria un’attività di costante raffreddamento degli ambienti in cui operano, un’attività che consuma ulteriore energia e moltissima acqua.
Si calcola che il sistema di raffreddamento di un data center per la computazione AI consumi circa il 40% dell’energia dell’intera struttura e che il suo utilizzo di acqua quotidiano sia pari a quello di mille nuclei familiari.
La svolta nucleare
Il carico computazionale richiesto dall’addestramento dei grandi modelli AI è tale che se dovessimo affidare a una sola GPU un’intera sessione di addestramento di ChatGPT, essa ci metterebbe 288 anni.
Per questo aziende come OpenAI utilizzano decine di migliaia di GPU per accelerare i tempi di esecuzione del compito. Secondo stime di Morgan Stanley l’addestramento di GPT-5 vede per esempio coinvolte 25.000 GPU di Nvidia (oltre ad altre tipologie di chip), per un costo complessivo di 250 milioni di dollari di solo hardware.
Come si diceva in precedenza, solo pochissime realtà – i cosiddetti hyperscaler – sono in grado di assemblare la quantità di hardware richiesta dall’addestramento delle AI (nonché di altre applicazioni particolarmente compute-intensive). Ciò ha implicazioni politiche molto serie che affronteremo meglio nella prossima puntata.
Tornando alle GPU, la progressione dei consumi energetici è chiara: un chip A100 di Nvidia (il meglio delle GPU fino a solo due anni fa) consumava 400W. Con il successivo H100 (2022), siamo passati a 700W. Con il prossimo B100, arriveremo a 1000W.
Intendiamoci: il rendimento di ognuno di questi chip è molto migliore del precedente (calcolano di più consumando meno), il problema è la complessiva crescita del loro utilizzo.
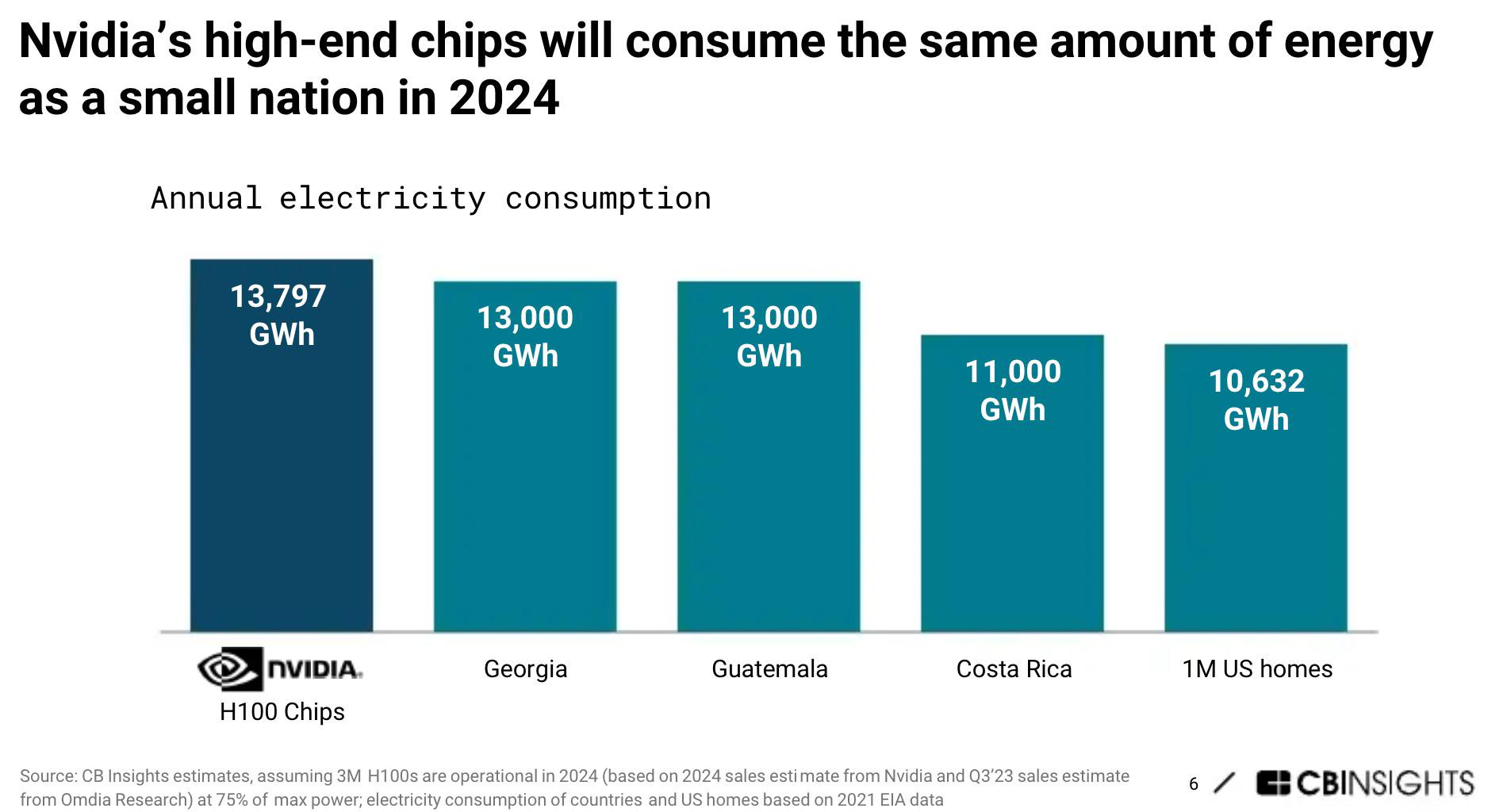
Anche in questo caso le lancette della Storia sembrano girare al contrario. Se negli anni Quaranta l’accensione dell’ENIAC mandava in crisi la rete elettrica di Philadelphia oggi, nell’epicentro della Silicon Valley, la proliferazione di data center ha portato la California al penultimo posto nella classifica nazionale della resilienza energetica.
Ma l’esplosione dei centri di computazione non comporta solo problemi energetici. Come ha raccontato il TIME a maggio, una città del Texas sta vivendo un’epidemia di emicranie, dagli effetti devastanti sulla salute dei cittadini, a causa del costante ronzio prodotto dai macchinari di un vicino, enorme data center (dedicato in questo caso all’estrazione di bitcoin, un’altra applicazione enormemente energivora).
Tutto ciò appare poco in linea coi richiami alla sostenibilità e alla lotta al “cambiamento climatico” che fino a pochi anni fa impregnavano l’ethos di buona parte del big tech.

Negli ultimi mesi abbiamo visto società di hyperscaler come Microsoft e Google ammettere candidamente di aver superato i limiti di emissioni che esse stesse si erano prefissate. In un report pubblicato a luglio, Google confessava che per la prima volta dal 2019 le sue emissioni erano cresciute del 48%, principalmente a causa di un aumento delle emissioni prodotte dai data center.
Tuttavia aziende come Google e Microsoft – che sono sia fornitrici di servizi di computazione a terzi, sia partecipanti dirette alla competizione per l’AI – considerano la leadership nel campo una questione di vita o di morte e non paiono disposte a rallentare la corsa.
E in effetti si stanno dimostrando pronte a investimenti notevolissimi pur di risolvere il dilemma energetico. Dato che fonti rinnovabili, come l’eolico o il solare, non sono abbastanza “stabili” per le necessità della computazione AI, gli hyperscaler stanno guardando altrove.
Di recente Google ha annunciato di aver ordinato sei piccoli reattori nucleari a una società specializzata della California, mentre Microsoft ha chiuso un accordo da 1,6 miliardi di dollari per riattivare la centrale di Three Mile Island (famigerata per un meltdown sfiorato nel 1979) e Amazon ha comprato da Talen Energy un data center direttamente connesso e alimentato da una vicina centrale nucleare.
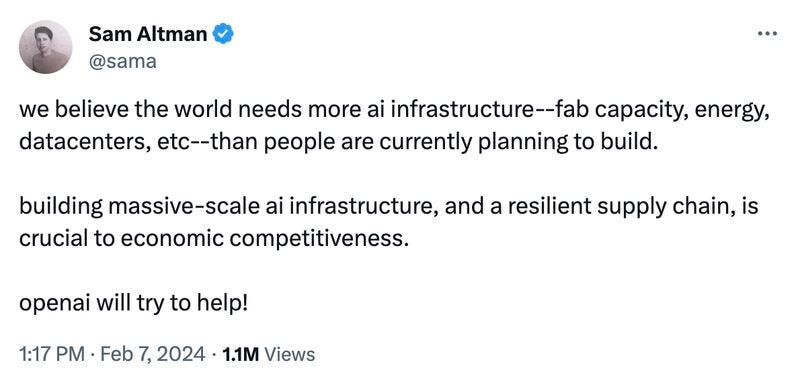
A fine settembre Bloomberg ha rivelato che il CEO di Open AI Sam Altman – non nuovo a simili sparate – avrebbe proposto a Biden la costruzione – con una mescola di investimenti pubblico-privati – di una serie di colossali data center da un milione di GPU ciascuno, tutti con annessi reattori capaci di soddisfare consumi pari a quelli di una città di medio-grandi dimensioni.
Il ruolo della politica
Davanti a simili problemi ci si potrebbe attendere la volontà degli Stati di porre un freno a un’escalation troppo rapida delle infrastrutture per la computazione AI.
Il fatto è che l’accelerazione dell'intelligenza artificiale sta avvenendo in contemporanea a una crisi sempre più profonda dell'ordine globale multilaterale. Qualunque “volontà di prudenza” si scontra perciò con la paura degli Stati – e in particolare delle due superpotenze contemporanee, Cina e Stati Uniti – di trovarsi attardati nella corsa a una tecnologia che è (o viene raccontata) come decisiva non solo a livello economico ma anche militare.
Il risultato è che anziché sulla necessità di mitigare le richieste di energia degli hyperscaler, il dibattito in merito si sta spostando sulla necessità di irrobustire le filiere di produzione, immagazzinamento e trasmissione dell’energia elettrica.
È probabile che la computazione AI stimolerà un’accelerazione degli investimenti, pubblici e non, in infrastrutture energetiche con conseguenze a doppio taglio.
Da un lato è evidente come qualunque mobilitazione di maggiori quantità di energia non possa essere in linea con obiettivi di sostenibilità a breve termine, dall’altra è chiaro che un aumento dei flussi di capitale nel settore potrebbe accelerare processi di innovazione – soprattutto per quanto riguarda l’efficienza dei sistemi di trasmissione e immagazzinamento – con ricadute positive sulle prospettive energetiche globali nel medio-lungo termine.
Il tema dell’escalation dei consumi connessi alla computazione AI ci dice anche altre cose. Per esempio che, nello sviluppo della tecnologia, sono avvantaggiati i paesi con una maggiore auto-sufficienza energetica. Il che rappresenta un problema non secondario per le ambizioni europee di autarchia nel campo delle infrastrutture della computazione (su tutte il progetto Gaia-X).
Come scrivevo ad aprile:
Nonostante gli sforzi per diversificare il mix energetico del continente, la produzione elettrica europea dipende infatti tra il 30% e il 45% (a seconda dei paesi) da costose importazioni di gas naturale. È evidente che, con simili statistiche, difficilmente l’Europa potrà sostenere a lungo la fame di elettricità dei data center in cui si addestrano le intelligenze artificiali. A dispetto delle roboanti dichiarazioni dei vertici dell’Unione in merito al desiderio di una maggiore autarchia tecnologica, questa situazione minaccia di porre un chiaro tetto materiale allo sviluppo di AI autoctone nel nostro continente, creando così i presupposti per una ulteriore dipendenza europea dall’estero.
Perché se è vero che i “large language models” si addestrano in cloud lo è anche che, ovviamente, la localizzazione geografica delle infrastrutture in cui essi fisicamente risiedono conta pur qualcosa. Già oggi il mercato dei data center sembra sempre più orientato a privilegiare altre mete rispetto alla “costosa” Europa, regioni con una maggiore disponibilità naturale di energia. Oltre agli Stati Uniti, una crescita degli investimenti in queste infrastrutture si sta perciò verificando in Medio Oriente, soprattutto in Arabia Saudita, Kuwait, Qatar ed Emirati Arabi. Paesi che, per ovvie ragioni, vantano alcune delle tariffe elettriche più economiche del pianeta.
È cosi che, intorno all’infrastruttura della computazione, vediamo avvilupparsi la più classica delle grandi questioni geopolitiche: la disponibilità di risorse naturali.
Per oggi ci fermiamo qui. Il tema della prossima puntata sarà appunto il potere che le suddette questioni geopolitiche esercitano sulle infrastrutture della computazione, e il potere che le infrastrutture della computazione esercitano sulle questioni geopolitiche.

Se siete nuovi da queste parti, io mi chiamo Cesare Alemanni. Mi interesso di questioni globali all’intersezione tra economia e geopolitica, tecnologia e cultura. Per Luiss University Press ho pubblicato La signora delle merci. Dalle caravelle ad Amazon, come la logistica governa il mondo (2023) e Il re invisibile. Storia, economia e sconfinato potere del microchip (2024).
