


Macro | 🖥️ Stati della computazione 🖥️
Chip, AI e infrastrutture del computing tra crisi geopolitiche, limite dell'innovazione e problemi energetici.


Affermare che viviamo nell’ “era digitale” è un luogo comune. Meno comune è ricordare come ciò che chiamiamo “era digitale” si regga in realtà su infrastrutture materiali che operano tramite computazione, ovvero per calcoli. Ancora meno ovvio è sottolineare come la complessità di tali sistemi, e dei relativi calcoli, non solo stia aumentando ma, come vedremo, per molti versi stia cambiando pelle. È chiamata ad affrontare problemi – di natura tecnica, politica, economica, etica, ecologica – inauditi. Problemi che aprono le porte a interrogativi che riguardano il futuro di intere società e modi di vivere.
Per questa ragione ritengo utile mettere insieme una specie di riepilogo, a scopo divulgativo, di quello che è lo “stato della computazione” contemporanea. Lo farò in più “puntate”, pensate per essere pubblicate sulla mia newsletter, Macro, e su quella di Stefano Feltri, Appunti. Questa è la prima: consideratela una sorta di introduzione.
La computazione è un’infrastruttura
Suppongo che se chiedessimo a cento italiani estratti a sorte di indicarci un computer, la stragrande maggioranza ci mostrerebbe un desktop o un laptop. Qualcuno probabilmente uno smartphone. Una percentuale minore citerebbe una console da videogiochi. Pochissimi un’automobile o un elettrodomestico.
Come dimostra mia madre ogni volta che, consultando il meteo di Google, esclama: “domani piove, lo dice il cellulare”, la maggioranza di noi continua a concepire la computazione come una specie di magia che avviene soltanto all’interno degli oggetti tecnologici in suo possesso ed è ad essi indissolubilmente legata. È un riflesso comprensibile. In fondo la computazione è entrata nelle nostre vite per prima cosa sotto forma di oggetti personali. Dopo i primi decenni di vita, in cui i computer occupavano intere stanze, negli anni Settanta la computazione ha cominciato a divenire un “oggetto di consumo”, una merce materiale. Si entrava in un negozio e se ne usciva con un personal computer. Un oggetto. Un po’ più tardi se ne usciva con scatole piene di manuali e di cd per installare software. Altri oggetti. Infine, ancora più in là, se ne usciva con Playstation, iPod, iPhone. Sempre e comunque oggetti.

In parallelo a questa storia, ne scorrevano però già altre. Una aveva a che fare con le dimensioni (minori), le capacità (maggiori) e i costi (più bassi) di quegli oggetti. Essa dipendeva dal processo, di per sé strabiliante, di miniaturizzazione dei transistor (i neuroni artificiali della computazione) contenuti nei chip. Un’evoluzione che ha fatto sì che la CPU del computer su cui scrivo contenga decine di miliardi di transistor nello spazio di pochi centimetri. Se volete un metro di paragone: nel primo microprocessore – l’Intel 4004 del 1971 – i transistor erano 2,300. Tuttavia, come racconteremo tra poco, questo processo di miniaturizzazione è oggi prossimo al suo limite fisico. E non solo, come vedremo in una successiva puntata, l’industria dei chip è, ormai da anni, al centro di una delle principali contese geopolitiche del nostro tempo.
Un’altra storia – comunque dipendente dalla precedente – aveva a che fare con la trasformazione della computazione da un fenomeno che avveniva principalmente all’interno di oggetti di fronte a noi, in un fenomeno che si svolgeva in luoghi distanti per esserci poi venduto sotto forma di servizi. Questa storia inizia – già negli anni Cinquanta – con i primi esperimenti di interconnessione dei computer in reti. Col tempo queste reti si inspessiscono e infittiscono. Cominciano a generare e immagazzinare informazione che non risiede più fisicamente nell’hardware di chi ne fa uso ma si trova altrove, dentro computer specializzati chiamati server, e viene distribuita attraverso cavi, fibre e segnali. Man mano che questo tipo di computazione avanza, e i servizi che offre divengono sempre più appariscenti nelle nostre vite, i server si fanno più potenti e numerosi, al punto che, per contenerli, diviene necessario costruire delle vere e proprie cattedrali della computazione: i famosi data center.
Questa seconda evoluzione è la ragione per cui, negli ultimi quindici anni, siamo divenuti dipendenti da social media, app, piattaforme; nonché il motivo per cui sentiamo quotidianamente parlare di big data, cyber-security e intelligenza artificiale. Benché spesso si presenti questo sviluppo con un termine etereo come cloud computing, o semplicemente cloud (nuvola), la realtà è che questa “nuvola” non ha nulla di impalpabile. Tutt’altro. Essa può fluttuare sopra le nostre teste solo grazie a una gigantesca infrastruttura materiale. O meglio, grazie a uno stack (pila) di infrastrutture che, tramite una serie di standard, connette, coordina e integra diversi livelli e protocolli di computazione.

Nanometri e infrastrutture
Tutto ciò che di rilevante accade oggi nell’universo della computazione accade nelle due principali dimensioni dello stack: la scala microscopica dei chip e dei transistor e quella macroscopica delle infrastrutture di accumulazione, elaborazione e distribuzione dei dati. Le due scale sono interdipendenti, nel senso che dalle direzioni, e dai ritmi, dello sviluppo di una dipende l’altra e viceversa. I problemi dell’una diventano spesso dell’altra e così via.
Questa interdipendenza esisteva già da parecchio ma negli ultimi dieci anni si è ulteriormente approfondita in virtù della crescita del settore dell’intelligenza artificiale che, più di ogni altro, rappresenta un punto di sutura tra le due dimensioni.
La peculiare tipologia di calcoli necessaria allo sviluppo dell’intelligenza artificiale non solo sta mutando l’infrastruttura della computazione ma sta anche esasperando alcune sue criticità. Come accennavo all’inizio, tali criticità sono di diversa natura, così come di diversa natura sono le loro conseguenze sul mondo in cui viviamo e vivremo.
Alla base dello stack dell’AI – le sue fondamenta, per così dire – c’è, come detto, il microchip, la particella elementare della computazione, dal cui sviluppo dipende da sempre la progressione della potenza di calcolo a nostra disposizione. Tale progressione è stata osservata, già agli esordi della tecnologia, da uno dei suoi pionieri: Gordon Moore. Il quale, nel 1965, notò che “la complessità di un chip, misurata ad esempio tramite il numero di transistor per chip, raddoppia ogni 18 mesi”. Questa osservazione, in seguito leggermente rivista (i mesi diventarono 24), è passata alla storia come “legge di Moore”.
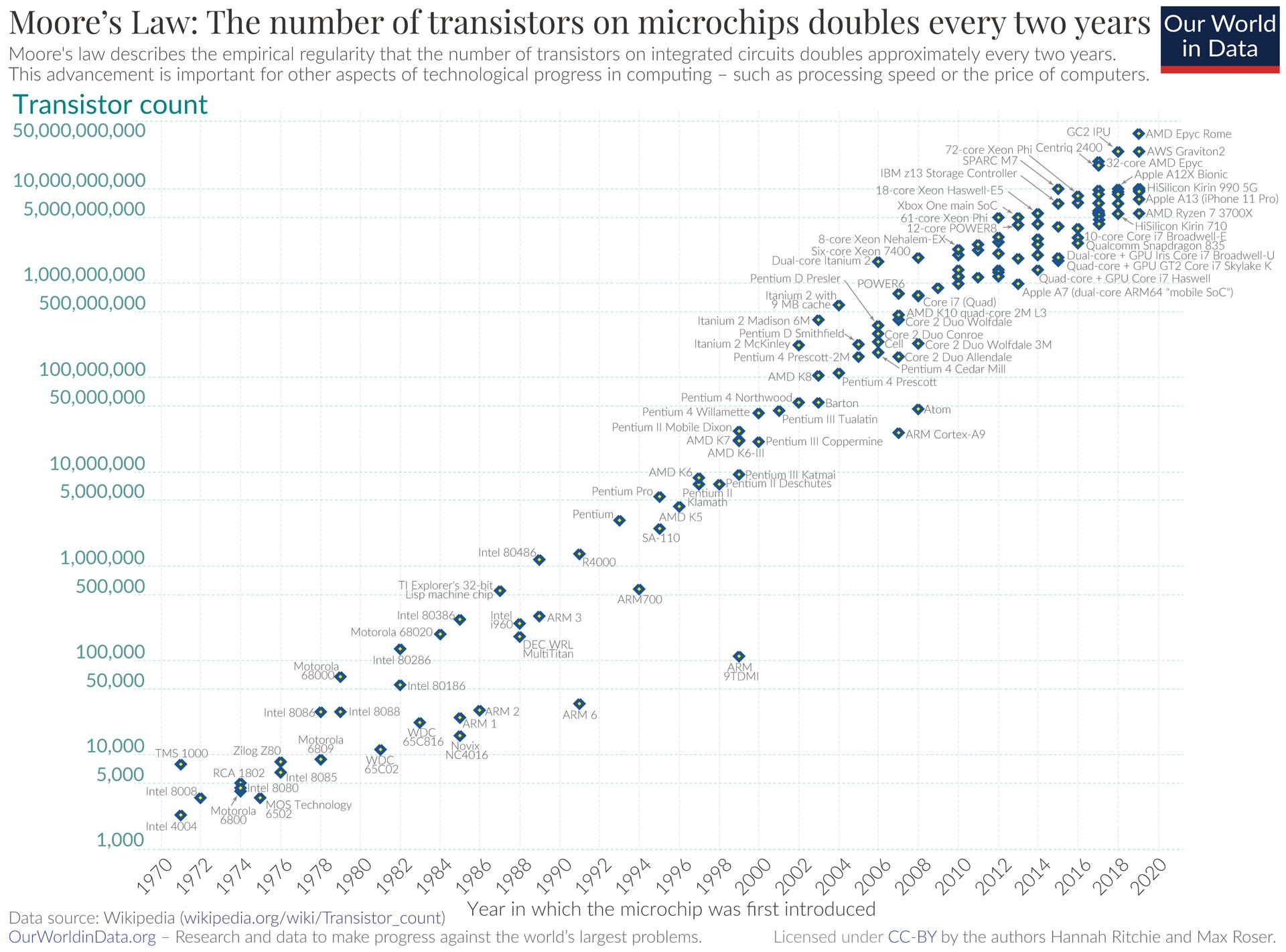
La “legge di Moore” tuttavia non è affatto una “legge”, nel senso in cui si intende il termine in campo matematico o fisico. La parola chiave in questo caso è “osservazione”. Nel 1965 Moore fece caso a una tendenza iniziale relativa all’aumento del numero dei transistor e si limitò a ipotizzare che tale tendenza sarebbe potuta durare per un certo periodo di tempo. La sua osservazione non aveva rigore scientifico né pretendeva di averlo. Tuttavia, anche grazie agli sforzi compiuti da scienziati e ingegneri per rispettarla, la “legge di Moore” è sopravvissuta per quasi mezzo secolo, garantendoci un’esplosione di potere di computazione a costi sempre più contenuti. È grazie alla validità della predizione di Moore se l’informatica si è (finora) presentata come un fenomeno sempre più inclusivo e se – come raccontavo poc’anzi – la computazione è entrata nelle nostre vite sotto forma di oggetti sempre più piccoli ed economici.
La “legge di Moore” non è purtroppo destinata a durare per sempre. I transistor possono essere rimpiccioliti solo fino a un certo punto. Dopodiché le leggi della fisica classica lasciano il posto a quelle della meccanica quantistica che rendono impossibile controllare i flussi di elettroni a fini computativi. Già oggi i transistor, e i fili che li connettono, sono misurati su scala atomica, poco più larghi di un filamento di DNAumano (2,5 nanometri). Sebbene resti ancora margine per rimpicciolirli, i progressi nella miniaturizzazione dei transistor diventano ogni anno più lenti e costosi e, in ogni caso, tra non molto dovranno arrendersi, come detto, di fronte a limiti fisici al momento invalicabili. Possiamo insomma discutere a lungo (e nell’industria dei chip lo si fa di continuo) se la legge di Moore sia ancora viva o se invece sia già morta (come suggeriscono alcuni indicatori) ma quel che è certo è che ci avviciniamo al suo capezzale.
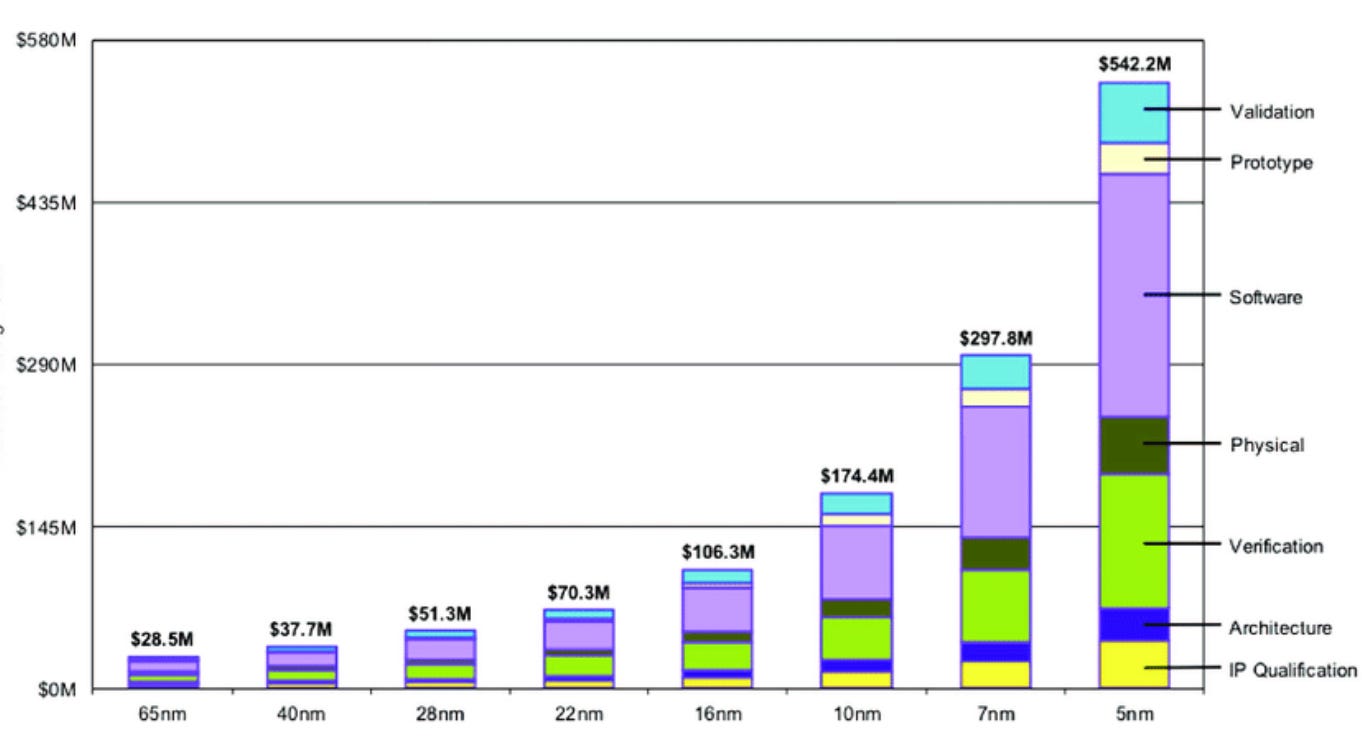
La “fine” della legge di Moore non solo sta spingendo alla ricerca di strumenti e sistemi computativi alternativi (ne parleremo in un prossimo episodio) ma sta portando all’estremo la complessità tecnica inerente alla progettazione e alla manifattura dei microchip, con effetti soprattutto economici. Il risultato è che il settore è oggi piagato da rendimenti decrescenti in termini di potere di computazione e da una ipertrofia dei costi che coinvolge l’intera catena del valore: macchinari di produzione da 300 milioni di dollari a pezzo, impianti che costano 12-20 miliardi per una singola fabbrica, ingegneri con costi e tempi di formazione elevatissimi e così via.
Tutto ciò si traduce nel fatto che, per esempio, lo sviluppo di Blackwell, la nuova architettura per GPU di Nvidia, ha richiesto all’azienda di Santa Clara un investimento di quasi 10 miliardi, per un prodotto che verrà immesso sul mercato a un prezzo che dovrebbe oscillare, a seconda della configurazione, tra i 30 e i 70mila dollari per esemplare. Cifre simili per un singolo pezzo di hardware sono una netta inversione rispetto alla tendenza a diventare più economica e personale che aveva contrassegnato la precedente fase della computazione. E infatti le GPU di Nvidia non sono un prodotto destinato a semplici consumatori, ma sono, a tutti gli effetti, un componente industriale altamente specializzato che viene principalmente utilizzato – con ordinazioni da decine di migliaia di pezzi al costo di centinaia di milioni di dollari – nei data center delle aziende del “big tech” che partecipano alla cosiddetta “corsa alla AI”.
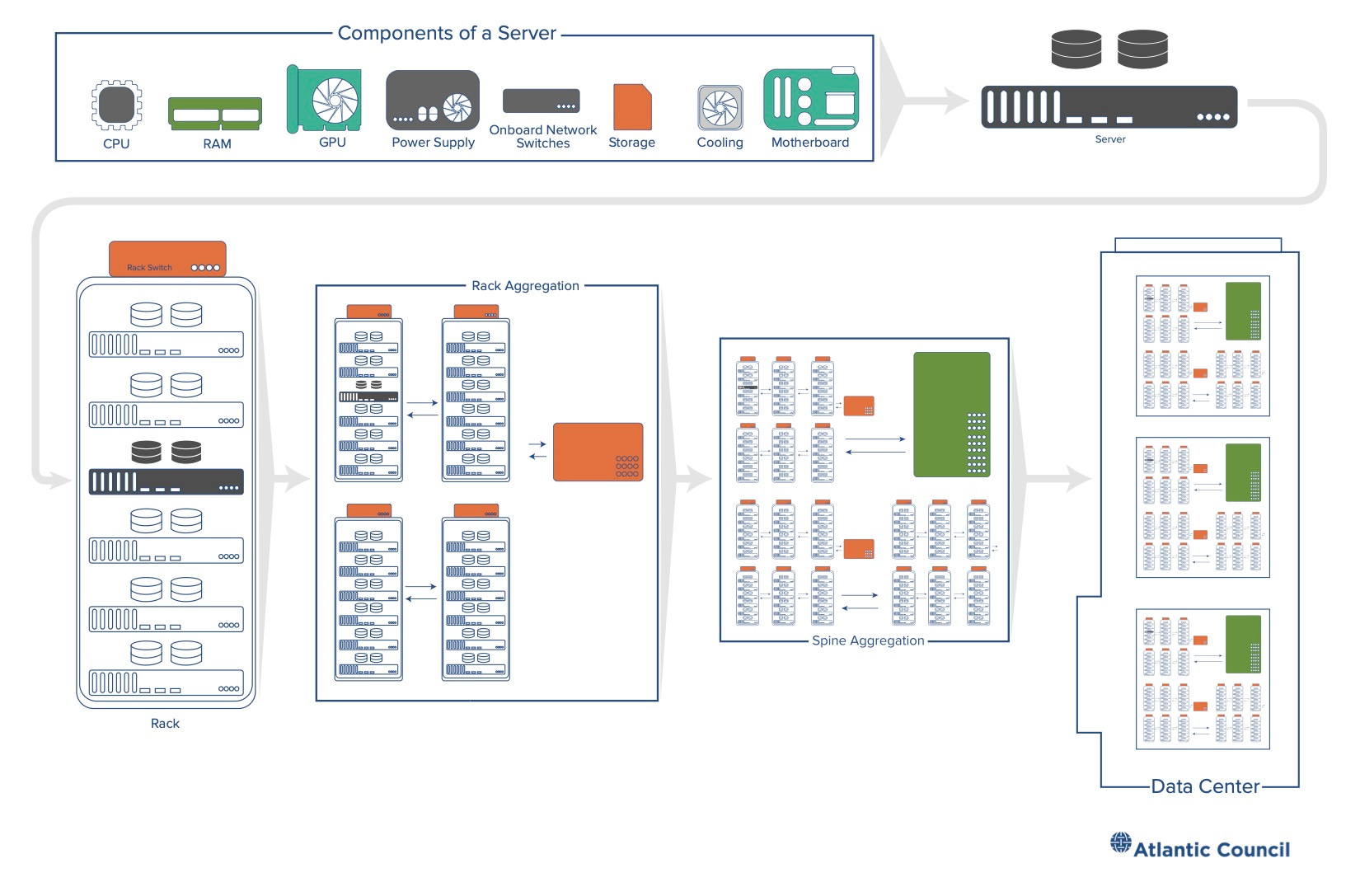
È intorno a questa corsa che oggi la storia “micro” dei chip e dei transistor, incrocia la dimensione “macro” delle infrastrutture della computazione legata all’addestramento dell’intelligenza artificiale. Il risultato di questo incontro è che 1) l’infrastruttura della computazione si sta sovraccaricando di enormi stress energetici ed ecologici e 2) si sta trasformando in un settore in cui la differenza tra perdite e profitti dipende da enormi economie di scala e di potere computazionale che solo una manciata di aziende, dalle tasche profondissime e dal know-how particolarmente vasto, possono raggiungere. Queste aziende sono oggi note come hyperscaler e il loro peso nell’infrastruttura della computazione, AI e non solo, è sempre più una questione con enormi ricadute geopolitiche ed economiche.
L’intuizione di Feynman
In precedenza ho scritto che il primo a parlare di miniaturizzazione dei chip fu, nel 1965, il futuro co-fondatore di Intel Gordon Moore. In realtà non è del tutto accurato.
In merito esistono intuizioni ancora precedenti, inclusa una nientemeno che di Richard Feynman, uno dei più geniali fisici del Novecento. Il 29 dicembre 1959, durante l’annuale incontro dell’American Physical Society presso il California Institute of Technology, Feynman tenne un discorso seminale per lo sviluppo delle nanotecnologie e della microelettronica. Sarebbe passato alla Storia con il titolo di “There’s plenty of room at the bottom” (“C’è un sacco di spazio laggiù in fondo”).
Feynman sosteneva che per aumentare la potenza di calcolo dei computer, non si doveva guardare verso l’alto – cioè verso un aumento delle dimensioni degli strumenti informatici – bensì in basso – “laggiù in fondo” – verso la miniaturizzazione dei componenti.
Nel ‘59 i computer erano attrezzature che occupavano intere stanze e consumavano quantità di energia enormi. Si racconta che ogni volta che l’ENIAC – il primo calcolatore di tipo “moderno” – veniva messo in funzione le luci di un quartiere di Philadelphia si affievolissero.
Le considerazioni di Feynman erano perciò non solo opportune ma tempestive specie se consideriamo che, proprio nel 1959, venne assemblato il primo circuito integrato monolitico (in altre parole: il primo chip). Ecco un passaggio:
Perché non possiamo renderli (i computer, ndR) molto piccoli, con piccoli fili, piccoli elementi – e per piccoli intendo davvero piccoli? Ad esempio, i fili dovrebbero avere un diametro di 10 o 100 atomi, e i circuiti dovrebbero essere larghi qualche migliaio di angstrom.
Tutti coloro che hanno analizzato la teoria logica dei computer sono giunti alla conclusione che le potenzialità dei computer sono molto interessanti – se potessero essere resi più complessi di diversi ordini di grandezza.
Se avessero milioni di volte più elementi, potrebbero fare valutazioni. Avrebbero il tempo di calcolare qual è il modo migliore per eseguire il calcolo che stanno per fare. Potrebbero scegliere il metodo di analisi che, data la loro esperienza, ritengono migliore.
[…]
Se volessimo costruire un computer che avesse tutte queste straordinarie capacità qualitative, dovremmo probabilmente farlo delle dimensioni del Pentagono. Questo presenta diversi svantaggi. Innanzitutto, richiederebbe troppo materiale; non ci sarebbe abbastanza germanio nel mondo per tutti i transistor da inserire in questo enorme aggeggio.
C'è anche il problema della generazione di calore e del consumo di energia […]. Ma un problema ancora più pratico è che il computer sarebbe limitato a una certa velocità. Acausa delle sue grandi dimensioni, ci vorrebbe un tempo finito per trasmettere le informazioni da un punto all'altro.
Detto che alcuni elementi contenuti nei computer attuali sono persino più piccoli di quelli immaginati da Feynman e che, negli anni Sessanta, si smise di produrre microchip in germanio, e si cominciò a farli di silicio, proprio per una questione di abbondanza di questo elemento, Feynman parla qui in modo esplicito della relazione tra l’aumento della potenza di calcolo e la possibilità che i computer sviluppino “capacità qualitative” assimilabili all’intelligenza umana. Ovvero ciò che oggi chiamiamo intelligenza artificiale.

Megachip
Feynman sarebbe probabilmente sorpreso nel constatare che, sebbene i transistor abbiano raggiunto dimensioni irrisorie, per far emergere le “straordinarie capacità qualitative” di cui parlava non è sufficiente un Pentagono. Servono svariati Pentagono.
Certo, non si tratta di un singolo computer “delle dimensioni del Pentagono”… ma di milioni di chip specializzati dentro decine di migliaia di cabinet all’interno di migliaia di data center. Le ultime cifre parlano di 11mila data center attivi nel mondo, per una superficie complessiva di circa un miliardo di metri quadrati, equivalenti a 1800 Pentagono o, se preferite, a più di cinque volte l’area del comune di Milano (qui un mio pezzo sul consumo di suolo di queste strutture).
Solo poco più del 20% dei data center ad oggi operativi è dedicato alla computazione per l’addestramento dell’AI ma la domanda di potere computazionale destinata a questo scopo è in grande crescita e, nei prossimi anni, si prevede un’esplosione edilizia nel settore.
Feynman sarebbe inoltre sorpreso dal fatto che, anziché continuare a rimpicciolirsi, di recente diversi hardware avanzati hanno cominciato a diventare più grandi. Questo fenomeno ha a che fare con le difficoltà connesse alla miniaturizzazione dei transistor che ho raccontato nella precedente puntata. Il problema è che oggi “laggiù in fondo” (ovvero nelle dimensioni più piccole della materia) non c’è più “un sacco di spazio” per incrementare la capacità di calcolo.
Per questo motivo numerose aziende, inclusa Nvidia, hanno cominciato a progettare processori sempre più grandi, così da aumentare il numero di transistor (e di core) che contengono senza doverli rimpicciolire. Se fino a pochi anni fa la maggioranza dei chip era grande come monete da pochi centesimi, oggi sono normali mega-chip grandi quanto piatti da portata.
Uno dei competitor in prospettiva più promettenti di Nvidia è un’azienda di San Diego relativamente giovane (è stata fondata nel 2015). Si chiama Cerebras e i suoi chip più grandi – i WSE-3 – sono grandi come un intero wafer, il termine tecnico con cui si indicano i dischi di silicio lavorato, da cui normalmente si ricavano decine di chip. Non per caso si parla di Wafer-scale integration.

L’idea di Cerebras è di fornire, su un singolo enorme chip, un sistema computativo pari alla potenza di numerose GP, in modo da semplificare l’assemblaggio e la programmazione dei cluster di computazione. Ciò è reso possibile dall’enorme quantità di transistor che un WSE racchiude in così tanto spazio: 2,8 triliardi. Anche il prezzo (mai ufficialmente divulgato dall’azienda) si presume extralarge: le voci parlano di 2/3 milioni a pezzo.

Ciò ci riporta al problema dell’accessibilità di questi hardware e al fatto che (al momento) sembriamo essere tornati a un tempo in cui i computer erano strumenti iper-specializzati e costosissimi, gestiti da poche entità che ne affittavano l’utilizzo un tanto all’ora. Esiste anche un’espressione – “big iron” – per indicare quell’epoca che alcuni credevano finita per sempre con l’avvento dei personal computer.
Anche se a ben vedere i super-computer e le grandi infrastrutture della computazione non hanno mai smesso di esistere in parallelo all’informatica di largo consumo, più di un economista ha segnalato come questo sviluppo rischi di tagliare fuori interi paesidal futuro di tecnologie critiche, con ricadute più ampie sui tassi di disuguaglianza economica tra – e all’interno degli – Stati (su questo torneremo nella prossima puntata, mentre nella quarta ci occuperemo di possibili soluzioni alternative).
Un’ulteriore criticità di questa tendenza – come ben sapeva Feynman – è che maggiore è la dimensione di un circuito e maggiore è la superficie che gli impulsi elettrici devono attraversare per farlo computare. Per questo, e per altri motivi, i mega-chip sono componenti tecnologici che, in assoluto, consumano più energia dei chip “normali” (oltre a richiedere molta più energia per essere prodotti, come racconto nel mio libro). E tuttavia potrebbero comunque essere una soluzione energicamente più efficiente rispetto alle configurazioni attualmente in uso.
Grandi infrastrutture, grandi consumi
Persino più dispendiose ed energivore dei mega-chip sono le attuali infrastrutture per la computazione AI, basate su data center in cui decine di migliaia di GPU ed altre componenti (TPU, DPU, NPU) vengono destinate all’addestramento di un singolo modello linguistico di grandi dimensioni (LLM).
Secondo l’Agenzia Internazionale dell’energia, nel 2022 il consumo di energia dei data center (non soltanto legati all’AI) è stato di 1,6 miliardi di gigajoules, ovvero il 2% del globale.
Le previsioni di crescita dei consumi connessi all’addestramento e all’utilizzo delle AIvanno dalla catastrofica stima secondo cui il processo consumerà il 20% (!) dell’elettricità globale già nel 2030 ad altre, più moderate (e francamente credibili), che prevedono una percentuale intorno al 4,5% (un’aumento del 160% rispetto all’inizio di questo decennio). Che è comunque moltissima energia per una singola applicazione.
Questa crescita non è solo dovuta alla quantità di hardware dispiegata ma alle caratteristiche intrinseche agli algoritmi per l’addestramento dell’AI. I quali comportano un continuo e ripetuto avanti e indietro – dalle memorie ai “cannoni” della computazione e viceversa – di colossali quantità di informazione all’interno dei database più grandi della Storia.
Questo intenso traffico è reso possibile dal movimento di elettroni all’interno di chip che per una ragione (leak indesiderati) o per l’altra (le dimensioni) dissipano sempre più energia sotto forma di calore.
Questa è anche la ragione fisica per cui i computer si scaldano e, tra tutte le tipologie di computer, i server sono quelli che si scaldano di più. Il che rende necessaria un’attività di costante raffreddamento degli ambienti in cui operano, un’attività che consuma ulteriore energia e moltissima acqua.
Si calcola che il sistema di raffreddamento di un data center per la computazione AI consumi circa il 40% dell’energia dell’intera struttura e che il suo utilizzo di acqua quotidiano sia pari a quello di mille nuclei familiari.
La svolta nucleare
Il carico computazionale richiesto dall’addestramento dei grandi modelli AI è tale che se dovessimo affidare a una sola GPU un’intera sessione di addestramento di ChatGPT, essa ci metterebbe 288 anni.
Per questo aziende come OpenAI utilizzano decine di migliaia di GPU per accelerare i tempi di esecuzione del compito. Secondo stime di Morgan Stanley l’addestramento di GPT-5 vede per esempio coinvolte 25.000 GPU di Nvidia (oltre ad altre tipologie di chip), per un costo complessivo di 250 milioni di dollari di solo hardware.
Come si diceva in precedenza, solo pochissime realtà – i cosiddetti hyperscaler – sono in grado di assemblare la quantità di hardware richiesta dall’addestramento delle AI (nonché di altre applicazioni particolarmente compute-intensive). Ciò ha implicazioni politiche molto serie che affronteremo meglio nella prossima puntata.
Tornando alle GPU, la progressione dei consumi energetici è chiara: un chip A100 di Nvidia (il meglio delle GPU fino a solo due anni fa) consumava 400W. Con il successivo H100 (2022), siamo passati a 700W. Con il prossimo B100, arriveremo a 1000W.
Intendiamoci: il rendimento di ognuno di questi chip è molto migliore del precedente(calcolano di più consumando meno), il problema è la complessiva crescita del loro utilizzo.
Anche in questo caso le lancette della Storia sembrano girare al contrario. Se negli anni Quaranta l’accensione dell’ENIAC mandava in crisi la rete elettrica di Philadelphia oggi, nell’epicentro della Silicon Valley, la proliferazione di data center ha portato la California al penultimo posto nella classifica nazionale della resilienza energetica.
Ma l’esplosione dei centri di computazione non comporta solo problemi energetici. Come ha raccontato il TIME a maggio, una città del Texas sta vivendo un’epidemia di emicranie, dagli effetti devastanti sulla salute dei cittadini, a causa del costante ronzio prodotto dai macchinari di un vicino, enorme data center (dedicato in questo caso all’estrazione di bitcoin, un’altra applicazione enormemente energivora).
Tutto ciò appare poco in linea coi richiami alla sostenibilità e alla lotta al “cambiamento climatico” che fino a pochi anni fa impregnavano l’ethos di buona parte del big tech.

Negli ultimi mesi abbiamo visto società di hyperscaler come Microsoft e Google ammettere candidamente di aver superato i limiti di emissioni che esse stesse si erano prefissate. In un report pubblicato a luglio, Google confessava che per la prima volta dal 2019 le sue emissioni erano cresciute del 48%, principalmente a causa di un aumento delle emissioni prodotte dai data center.
Tuttavia aziende come Google e Microsoft – che sono sia fornitrici di servizi di computazione a terzi, sia partecipanti dirette alla competizione per l’AI – considerano la leadership nel campo una questione di vita o di morte e non paiono disposte a rallentare la corsa.
E in effetti si stanno dimostrando pronte a investimenti notevolissimi pur di risolvere il dilemma energetico. Dato che fonti rinnovabili, come l’eolico o il solare, non sono abbastanza “stabili” per le necessità della computazione AI, gli hyperscaler stanno guardando altrove.
Di recente Google ha annunciato di aver ordinato sei piccoli reattori nucleari a una società specializzata della California, mentre Microsoft ha chiuso un accordo da 1,6 miliardi di dollari per riattivare la centrale di Three Mile Island (famigerata per un meltdown sfiorato nel 1979) e Amazon ha comprato da Talen Energy un data center direttamente connesso e alimentato da una vicina centrale nucleare.
A fine settembre Bloomberg ha rivelato che il CEO di Open AI Sam Altman – non nuovo a simili sparate – avrebbe proposto a Biden la costruzione – con una mescola di investimenti pubblico-privati – di una serie di colossali data center da un milione di GPU ciascuno, tutti con annessi reattori capaci di soddisfare consumi pari a quelli di una città di medio-grandi dimensioni.
Il ruolo della politica
Davanti a simili problemi ci si potrebbe attendere la volontà degli Stati di porre un freno a un’escalation troppo rapida delle infrastrutture per la computazione AI.
Il fatto è che l’accelerazione dell'intelligenza artificiale sta avvenendo in contemporanea a una crisi sempre più profonda dell'ordine globale multilaterale. Qualunque “volontà di prudenza” si scontra perciò con la paura degli Stati – e in particolare delle due superpotenze contemporanee, Cina e Stati Uniti – di trovarsi attardati nella corsa a una tecnologia che è (o viene raccontata) come decisiva non solo a livello economico ma anche militare.
Il risultato è che anziché sulla necessità di mitigare le richieste di energia degli hyperscaler, il dibattito in merito si sta spostando sulla necessità di irrobustire le filiere di produzione, immagazzinamento e trasmissione dell’energia elettrica.
È probabile che la computazione AI stimolerà un’accelerazione degli investimenti, pubblici e non, in infrastrutture energetiche con conseguenze a doppio taglio.
Da un lato è evidente come qualunque mobilitazione di maggiori quantità di energia non possa essere in linea con obiettivi di sostenibilità a breve termine, dall’altra è chiaro che un aumento dei flussi di capitale nel settore potrebbe accelerare processi di innovazione – soprattutto per quanto riguarda l’efficienza dei sistemi di trasmissione e immagazzinamento – con ricadute positive sulle prospettive energetiche globali nel medio-lungo termine.
Il tema dell’escalation dei consumi connessi alla computazione AI ci dice anche altre cose. Per esempio che, nello sviluppo della tecnologia, sono avvantaggiati i paesi con una maggiore auto-sufficienza energetica. Il che rappresenta un problema non secondario per le ambizioni europee di autarchia nel campo delle infrastrutture della computazione (su tutte il progetto Gaia-X).
Come scrivevo ad aprile:
Nonostante gli sforzi per diversificare il mix energetico del continente, la produzione elettrica europea dipende infatti tra il 30% e il 45% (a seconda dei paesi) da costose importazioni di gas naturale. È evidente che, con simili statistiche, difficilmente l’Europa potrà sostenere a lungo la fame di elettricità dei data center in cui si addestrano le intelligenze artificiali. A dispetto delle roboanti dichiarazioni dei vertici dell’Unione in merito al desiderio di una maggiore autarchia tecnologica, questa situazione minaccia di porre un chiaro tetto materiale allo sviluppo di AI autoctone nel nostro continente, creando così i presupposti per una ulteriore dipendenza europea dall’estero.
Perché se è vero che i “large language models” si addestrano in cloud lo è anche che, ovviamente, la localizzazione geografica delle infrastrutture in cui essi fisicamente risiedono conta pur qualcosa. Già oggi il mercato dei data center sembra sempre più orientato a privilegiare altre mete rispetto alla “costosa” Europa, regioni con una maggiore disponibilità naturale di energia. Oltre agli Stati Uniti, una crescita degli investimenti in queste infrastrutture si sta perciò verificando in Medio Oriente, soprattutto in Arabia Saudita, Kuwait, Qatar ed Emirati Arabi. Paesi che, per ovvie ragioni, vantano alcune delle tariffe elettriche più economiche del pianeta.
È cosi che, intorno all’infrastruttura della computazione, vediamo avvilupparsi la più classica delle grandi questioni geopolitiche: la disponibilità di risorse naturali.
Dipendenze
Secondo gli esperti è impossibile prevedere di quanto cresceranno le esigenze computazionali connesse all’AI ma è pressoché certo che, nel medio termine, il loro costo continuerà ad aumentare.
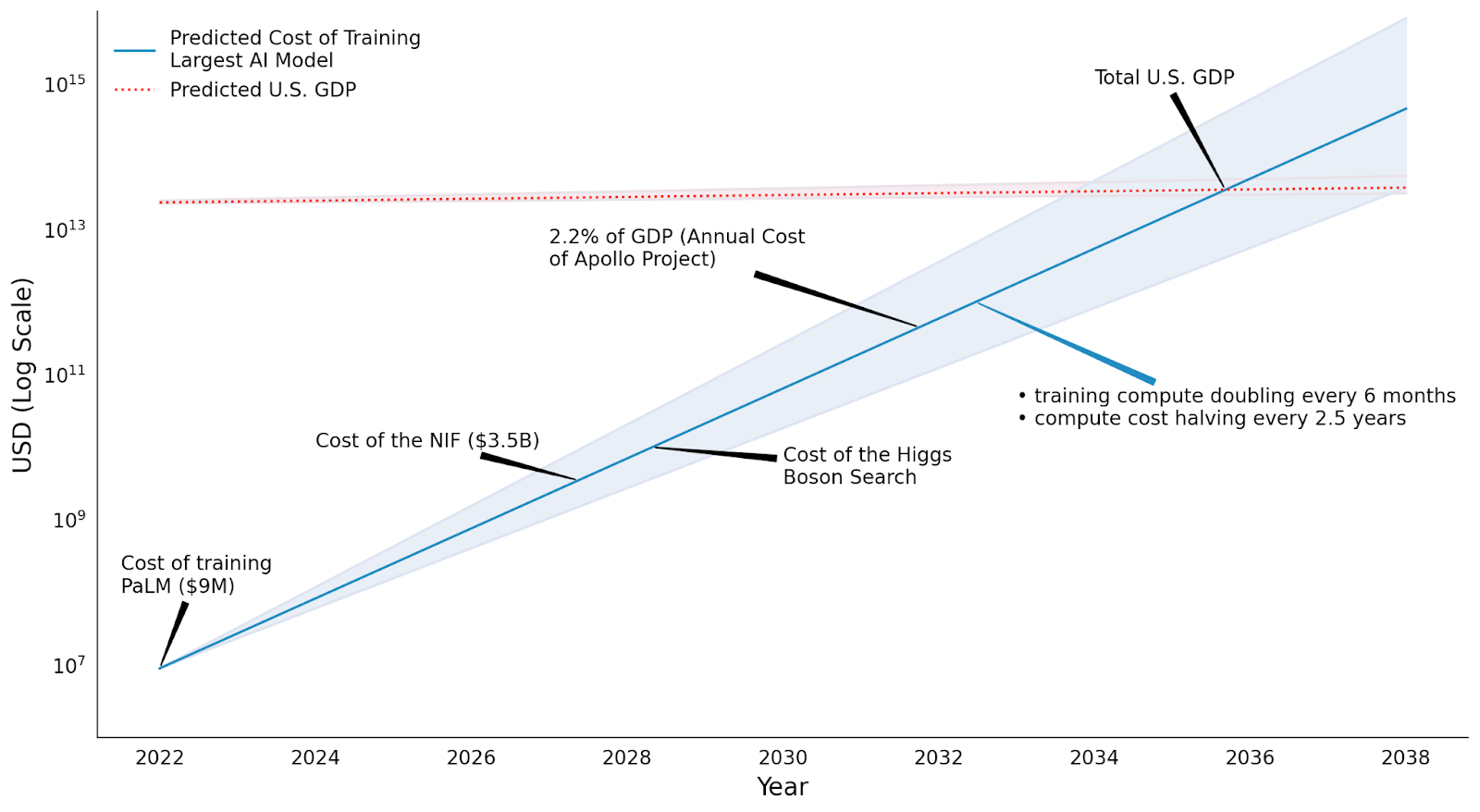
Ciò fa sì che lo sviluppo dell’intelligenza artificiale sia un’operazione al momento accessibile solo a un ristretto grappolo di aziende.
E infatti la maggioranza delle attività di addestramento dell’AI si svolge nelle strutture dei cosiddetti hyperscaler: Oracle, Microsoft Azure, Google Cloud, IBM Cloud e Amazon Web Services per l’emisfero occidentale; Alibaba, Tencent, Huawei per la sfera d’influenza cinese.
A causa della scala dei costi e della potenza di computazione che richiedono i loro modelli, pressoché tutti i più promettenti laboratori indipendenti sull’AI sono finiti sotto l’ombrello di alcuni di questi soggetti: OpenAI con Microsoft, DeepMind e Anthropic con Google, Hugging Face con Amazon etc.
L’accelerazione dell’AI sta in altre parole consolidando l’influenza di alcune aziendeche già dominavano il mercato delle infrastrutture della computazione e il precedente ciclo del capitalismo digitale.
Il risultato è che più le AI diventeranno strumenti indispensabili per le nostre società e più esse diventeranno dipendenti – tanto per l’addestramento quanto per l’uso quotidiano – da sistemi di proprietà di una manciata di aziende private.
La dipendenza da pochi fornitori di infrastrutture computazionali può inoltre avere conseguenze significative anche sulla capacità di innovazione.
Quando la maggior parte dei laboratori di ricerca deve fare affidamento sugli hyperscaler per avere accesso alle risorse computazionali, , le dinamiche di sviluppo tecnologico vengono plasmate dagli interessi di questi ultimi. Il che può tradursi in una limitazione nella varietà dell’innovazione.
Il paradosso della computazione
In The Stack, un libro molto ambizioso sull’argomento, il filosofo/informatico Benjamin Bratton, insiste sulla caratteristica inedita, e per certi versi paradossale, delle infrastrutture della computazione.
Ovvero il fatto di essere, per un verso, realtà materiali con confini geografici e giuridiciben precisi e per l’altro produrre servizi ed effetti immateriali che quei confini li attraversano di continuo. E, soprattutto, di determinare, con i loro standard digitali, la cornice tecnica entro cui si svolgono fondamentali istituzioni socio-politiche del mondo fisico, dal mercato alle amministrazioni pubbliche di innumerevoli paesi.
Per capire le problematiche insite nell’influenza geopolitica dello stack della computazione, è necessario rimarcare soprattutto il primo aspetto, cioè quello della materialità dell’infrastruttura.
Perché se è vero che i data center sono centri di trattamento e distribuzione di “valori” immateriali come i dati, è anche vero che il fatto che essi si trovino in un luogo piuttosto che in un altro fa enormi differenze.
Le tecnologie digitali saranno anche il nuovo petrolio ma a differenza del petrolio non è la natura a decidere dove si trovano i loro “giacimenti”, bensì persone, aziende, istituzioni, Stati.
E oggi, perlomeno in Occidente, le uniche aziende in grado di agire da hyperscaler per l’AI rispondono, in ultima istanza, a un solo Stato, gli USA.
Per non dire del fatto che quasi il 90% dei dati prodotti in Occidente – inclusi quelli di governi, amministrazioni pubbliche, persino eserciti – sono immagazzinati in server di proprietà di corporation americane.
Velleità europee
Nell’era del Trump-bis (ma anche prima), per l’Europa la geopolitica della computazione dovrebbe essere causa di profonde riflessioni.
Perché se è vero che oggi sempre più provider di computing in cloud promettono ai loro clienti la “sovranità digitale” – ovvero che i dati saranno gestiti in modo conforme alle leggi del loro Paese di origine e che non verranno condivisi con enti al di fuori di esso – ci si può chiedere che valore abbia una sovranità “fornita” a guisa di servizio e come promessa di “buona condotta”; a fronte di una dipendenza che è invece del tutto effettuale.
In risposta a queste considerazioni, nell’ormai lontano 2019 Francia e Germania hanno lanciato Gaia-X. Descritto dall’allora ministro dell’economia tedesco Peter Altmaier come “qualcosa che somiglia a un Airbus dell’intelligenza artificiale”, Gaia-X rappresentava il tentativo delle due principali economie europee di dotare l’Europa di un “campione continentale” della computazione in cloud.

L’iniziativa di Gaia-X nasceva sulla scorta di una serie di fallimentari progetti nazionali con intenti simili, tra cui spicca il francese Projet Andromède.
A più di cinque anni dal suo lancio e a più di quattro dalla sua messa in moto, Gaia-X non ha ancora prodotto nulla di paragonabile all’ambizione con cui era stato presentato e – oltre che alle croniche difficoltà di governance di tutti i progetti europei– si è, per ora, dovuto arrendere alla constatazione che senza un ecosistema finanziario e tecnologico dell’innovazione paragonabile a quello del Big Tech americano è pressoché impossibile sottrarsi al “colonialismo digitale” degli USA.
E infatti dopo pochi mesi dagli annunci di Altmaier, Gaia-X ha annunciato l’adesione al progetto di Microsoft, Amazon e Google e persino Palantir. In pratica ciò che si cercava di fare uscire dalla porta è rientrato dalla finestra.
Nel frattempo da progetto con obiettivi concreti, negli ultimi due anni, Gaia-X sembra essersi trasformato nell’ (ennesima) fondazione europea orientata a mettere in campo indicazioni di policy più che cabinet di server (i suoi responsabili sostengono che questa sia sempre stata l’intenzione, con buona pace di Altmaier e dell’Airbus).
Il ridimensionamento degli orizzonti di Gaia-X non ha impedito a diversi leader europei di continuare a fare velleitari proclami in merito a imprecisati progetti di “sovranità digitale” che tuttavia spesso si rivelano giganti coi piedi di argilla.
Se si scorrono le dichiarazioni in merito ai temi delle infrastrutture del computing, rilasciate negli ultimi 10/15 anni da politici e commissari europei di turno, si ha la sensazione di vivere in una specie di “giorno della marmotta” in cui, discorso dopo discorso, vengono ripetute pressoché le stesse esatte formule senza che nel frattempo avvenga nulla di rilevante.
La guerra dei chip
La materialità dei centri di calcolo si intreccia con le nuove “guerre” tecnologiche tra Cina e USA, in particolare sui chip, il nucleo atomico dell’infrastruttura del computing.
Come ho scritto nella prima puntata di questa serie: “tutto ciò che di rilevante accade oggi nell’universo della computazione accade nelle due principali dimensioni dello stack: la scala microscopica dei chip e dei transistor e quella macroscopica delle infrastrutture di accumulazione, elaborazione e distribuzione dei dati”. Ciò vale, ovviamente, anche per la geopolitica.
Oggi l’addestramento e lo sviluppo dell’AI dipendono in gran parte dalla disponibilità di grandi quantità di chip avanzati, progettati principalmente da Nvidia ma sempre più anche dalle stesse aziende di hyperscaler.
La catena del valore dei chip avanzati è estremamente complessa – al contempo molto distribuita geograficamente e altamente concentrata – e ciò la rende vulnerabile a tensioni geopolitiche e ad ambizioni politiche di controllo.
Da una parte abbiamo infatti un polo dell’innovazione che si trova soprattutto negli Stati Uniti, con aziende come Nvidia, Amd, Qualcomm, Intel (oggi in difficoltà, per ragioni che vedremo nella prossima puntata), e i soliti noti del big tech (Google, Apple etc) che progettano e disegnano i chip più avanzati del mondo e i software per ricavarne il massimo della potenza.
Dall’altra abbiamo un centro della manifattura che, per quanto riguarda i chip destinati alla computazione AI, si concentra quasi interamente a Taiwan e intorno all’azienda TSMC. Nel mezzo c’è una miriade di aziende iper-specializzate in diverse parti del processo, come l’olandese ASML che produce macchinari di fantascientifica complessità per la litografia dei transistor.
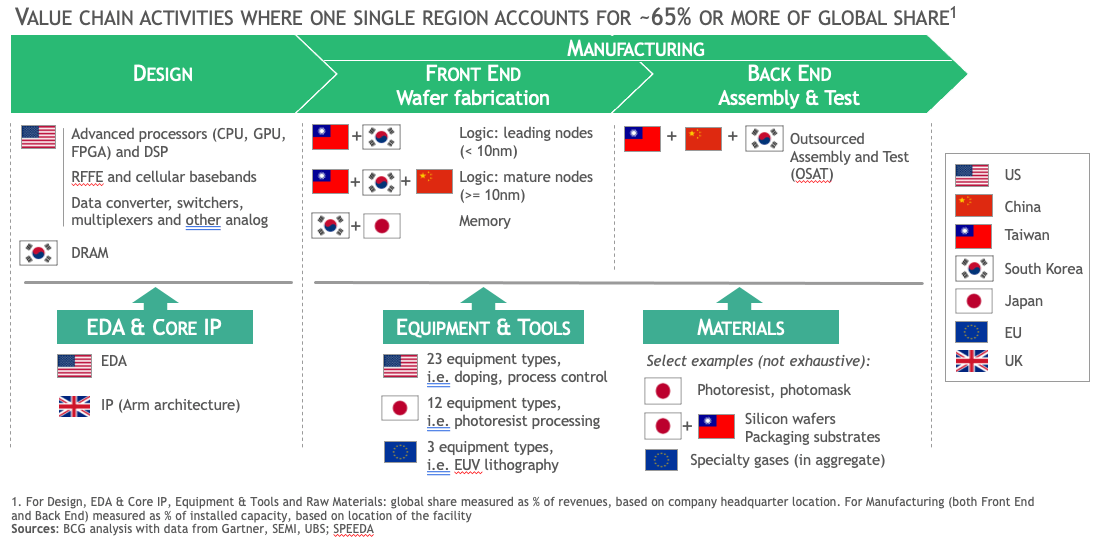
Constatato come i chip stiano all’avanzamento dell’AI come la farina a una focaccia, nell’ultimo decennio gli Stati Uniti hanno individuato proprio in questo fondamentale componente, lo snodo da presidiare per rallentare i progressi della Cina nel campo. Prima Obama, quindi Trump e infine (soprattutto) Biden hanno cercato, con diverse modalità, di mettere il bastone tra le ruote allo sviluppo AI cinese proprio partendo dai chip.
Dal 7 ottobre 2022, il Bureau of Industry and Security (BIS), l’ufficio del Dipartimento del Commercio USA che si occupa degli scambi con un potenziale impatto sulla sicurezza americana, ha posto il veto sull’esportazione in Cina di chip avanzati, in particolare quelli utilizzati nei data center per l’AI, ovvero le GPU disegnate da Nvidia e prodotte da TSMC, ma anche le attrezzature per produrre tali chip, incluse quelle di aziende europee come ASML o giapponesi come Nikon.
Come si poteva leggere nella nota di comunicazione che lo accompagnava, il provvedimento mirava a:
“limitare la capacità della Repubblica Popolare Cinese di ottenere e produrre chip avanzati e di sviluppare e mantenere supercomputer. Questi strumenti e competenze sono impiegati dalla Repubblica Popolare Cinese per realizzare sistemi militari incluse armi di distruzione di massa, aumentare la velocità e la precisione nei processi di pianificazione e logistica militare, oltre che nei suoi sistemi di attacco autonomi”.
Il legame tra infrastrutture della computazione e rivalità tra superpotenze, tra AI e sicurezza non poteva essere espresso in modo più esplicito.
Resta tuttavia un problema. E ovvero che le regole non è sufficiente scriverle ma bisogna anche farle rispettare. E infatti sempre nella stessa nota si leggeva: “la capacità del BIS di determinare se una parte rispetta le nostre normative sul controllo delle esportazioni è un principio fondamentale del nostro programma”.
Tra il dire e il fare c’è di mezzo il mare ed è, per esempio, notizia recentissima il ritrovamento di un componente avanzato prodotto da TSMC all’interno di un processore per l’AI del colosso cinese Huwaei.
TSMC ha immediatamente notificato l'accaduto al Dipartimento del Commercio statunitense, sottolineando che dal 2020 non rifornisce direttamente Huawei e che dunque i chip devono essere arrivati fino a lì tramite un sistema di aziende intermediarie e una filiera di scatole cinesi.
Presa per buona la parola di TSMC, la vicenda ha spinto gli americani a riesaminare le proprie misure di controllo e ad inasprire ulteriormente le limitazioni.
Rimane il fatto che questo episodio – come altri seppure meno clamorosi che lo hanno preceduto – evidenzia la complessità del mantenere il controllo sulle catene dell’approvvigionamento tecnologico e lascia più di un dubbio sull’effettiva efficacia delle restrizioni americane sugli hardware.
Tali restrizioni tuttavia raccolgono un consenso bipartisan talmente convinto che si può prevedere che continueranno, insieme a una marea montante di tariffe più “generiche”, anche durante l’amministrazione Trump.
Nel frattempo possiamo dare per certo che nei prossimi anni Cina e USA continueranno a investire centinaia di miliardi per ottenere, nel modo più univoco possibile, la supremazia tecnologica nell’ambito dei chip, delle infrastrutture della computazione e dello sviluppo delle applicazioni AI.
Tuttavia appare sempre più chiaro che la costituzione di filiere del tutto autonome e autosufficienti – tanto nell’ambito “duro” dell’infrastruttura quanto in quello “morbido” della ricerca e del software – sia impresa difficile da districare dalle logiche globali d’interdipendenza dentro cui è nata e cresciuta negli ultimi decenni di relativa “pax commerciale”.
Lo scacco del futuro
Nella politica internazionale contemporanea, l'accesso alle risorse computazionali per l’AI sta diventando un elemento strategico al pari delle risorse energetiche o delle materie prime.
Le grandi potenze hanno quindi iniziato a considerare le infrastrutture computazionali come una nuova frontiera per la proiezione del proprio potere globale, cominciando una “corsa alle armi digitali” che in teoria potrebbe definire i rapporti internazionali dei prossimi decenni.
Ci sono tuttavia alcune variabili da tenere in considerazione. La principale è che il modo in cui le AI vengono addestrate e utilizzate potrebbe cambiare nei prossimi anni. Nuove tecnologie stanno infatti rendendo possibile la decentralizzazione della computazione AI attraverso architetture innovative come la computazione edge e i chip specializzati per il calcolo AI in locale (il cosiddetto on-device AI).
Questi sviluppi favorirebbero l’autonomia di Stati e aziende nello sviluppo di capacità di calcolo AI, riducendo la loro dipendenza dalle piattaforme hyperscaler.
Ciò non avrebbe solo un impatto tecnologico, ma trasformerebbe anche gli equilibri geopolitici in merito. Un futuro senza la dominanza degli hyperscaler potrebbe aprire la strada a un’era di maggiore pluralismo tecnologico che influenzerebbe profondamente i rapporti di potere tecnologico tra Stati.
C’è inoltre la possibilità, spesso trascurata nei conciliaboli su questi temi, che nuove soluzioni emergano non dal versante dell’hardware ma da quello del software e degli algoritmi.
Già oggi, AlphaFold, una delle applicazioni AI più interessanti e utili sul pianeta (tanto da essere stata premiata con l’ultimo Nobel per la chimica) che si occupa dell’analisi della struttura delle proteine, utilizza appena lo 0,003% del potere di computazione richiesto da un “grande modello linguistico” come quelli che utilizza Chat-GPT.
Uno dei motivi è che AlphaFold fa uso di dataset più specifici e ristretti rispetto a un’AI generativa. Ma è possibile ipotizzare che questa specializzazione divenga, in futuro, più comune e diffusa in altri campi, riducendo quindi il carico computazionale richiesto da ogni singolo modello.
La stessa riduzione del carico di computing potrebbe essere ottenuta anche da un miglioramento nell’efficienza degli algoritmi di addestramento e inferenza. Non è quindi detto che sarà sempre e solo la mera “potenza di computazione” la variabile determinante per definire il livello di sviluppo di un sistema AI, rendendo quindi “futili” gli sforzi di controllare la catena del valore dal lato dell’hardware (come fanno oggi gli USA).
È questa una possibilità che anche i decisori europei dovrebbero tenere maggiormente presente. Dato che le scale dei giganti del cloud si sono rivelate inattaccabili, anziché tentare di scalarle probabilmente invano, sarebbe forse più utile provare a capire se esistono modi per aggirarle prima che siano altri a trovarli.
L’epopea Intel
Nel corso di questo articolo ho nominato spesso la “legge di Moore”, ovvero l’osservazione che il numero di transistor per chip – e quindi la loro capacità di calcolo – raddoppia in media ogni due anni. Quello che non ho raccontato forse abbastanza è chi fosse il suo “profeta”, il chimico Gordon Moore (1929 - 2023).
Moore è stato uno dei grandi protagonisti della microelettronica novecentesca. Ha fatto parte dei celebri “traitorous eight”, il gruppo di otto che, a fine anni Cinquanta, abbandonò uno dei padrini dell’intera disciplina, William Shockley – uomo di leggendario narcisismo – per passare a Fairchild Semiconductors, dove nacque a tutti gli effetti la produzione di massa dei chip, e infine co-fondò, insieme a Bob Noyce, un’azienda che è sinonimo di informatica: Intel.

Nata nello stesso anno – il 1968 – in cui milioni di giovani occidentali speravano di cambiare il mondo a colpi di slogan, Intel il mondo lo ha cambiato davvero. Nei suoi 56 anni di vita, l’azienda ha creato quasi da sola il mercato dell’informatica di largo consumo, grazie alla sua capacità di miniaturizzare i transistor e di estendere per decenni la validità della legge di Moore, rendendo in tal modo più economici, maneggevoli e potenti i computer.
Oggi Intel versa tuttavia in uno stato di profonda crisi. Una situazione che si deve a errori specifici dei suoi vertici ma che fa da cartina di tornasole dello “stato della computazione” contemporanea.
Un errore vitale
Le radici della crisi di Intel affondano nella metà degli anni Zero, quando l’allora CEO Paul Otellini disse un clamoroso no all’offerta di Steve Jobs di produrre i chip per un nuovo dispositivo su cui Apple puntava moltissimo: l’iPhone.
Otellini era convinto che non fosse un buon affare. Due miliardi e mezzo di iPhone venduti in nemmeno vent’anni la dicono diversamente e spiegano perché, ancora oggi, il suo niet riecheggi come un anatema tra i corridoi di Intel a Santa Clara.
L’errore di Otellini danneggiò Intel anche indirettamente. L’ascesa degli smartphone infatti non contribuì solo a ridurre le quote di mercato dei PC, i principali “consumatori” di chip Intel, ma plasmò l’intero ecosistema della computazione. Gli smartphone furono infatti il perno decisivo per il successo delle piattaforme e per l’affermazione del cloud computing.
Questa svolta erose ulteriormente la diffusione dei PC e mandò in crisi il mercato dei chip logici (CPU) in cui storicamente Intel era leader grazie alla sua architettura x86, il gold standard del settore.

Negli anni Dieci tale standard venne messo in discussione dai giganti degli smartphone prima e del cloud computing poi. I quali iniziarono a esplorare soluzioni alternative, inclusa la possibilità di sviluppare architetture diverse da quelle di Intel, a partire da matrici fornite dall’inglese ARM Holdings.
Il cambiamento del mercato dell’informatica di largo consumo derivato dall’introduzione degli smartphone, e l’accelerazione che ciò impresse al ritmo dell’innovazione dei chip, resero ancora più vantaggioso lo scorporo dell’industria in due rami che era cominciato già negli anni Ottanta.
Ovvero da una parte aziende “fabless”, che si occupano solo di progettazione (come Nvidia) e dall’altra aziende “foundry”, che si occupano solo di manifattura (come TSMC). Esattamente l’opposto del modello “integrato” di Intel, una delle pochissime aziende IDM (Integrated Device Manufacturer) che ancora svolge entrambe le fasi.
Intel si è trovata così a competere su due fronti contro aziende specializzate solo in uno e ha finito per perdere quote di mercato su entrambi. Anche perché nel frattempo l’emergere del calcolo parallelo per la computazione AI, ha portato a prediligere le famose GPU, chip molto diversi dai chip logici, e in cui Nvidia partiva con un vantaggio tecnologico e di mercato incolmabile (anche per una precedente scelta di Intel di non investire nella tecnologia).
Per anni Intel è riuscita a celare l’entità della crisi ma negli ultimi mesi essa è emersa in modo fragoroso.
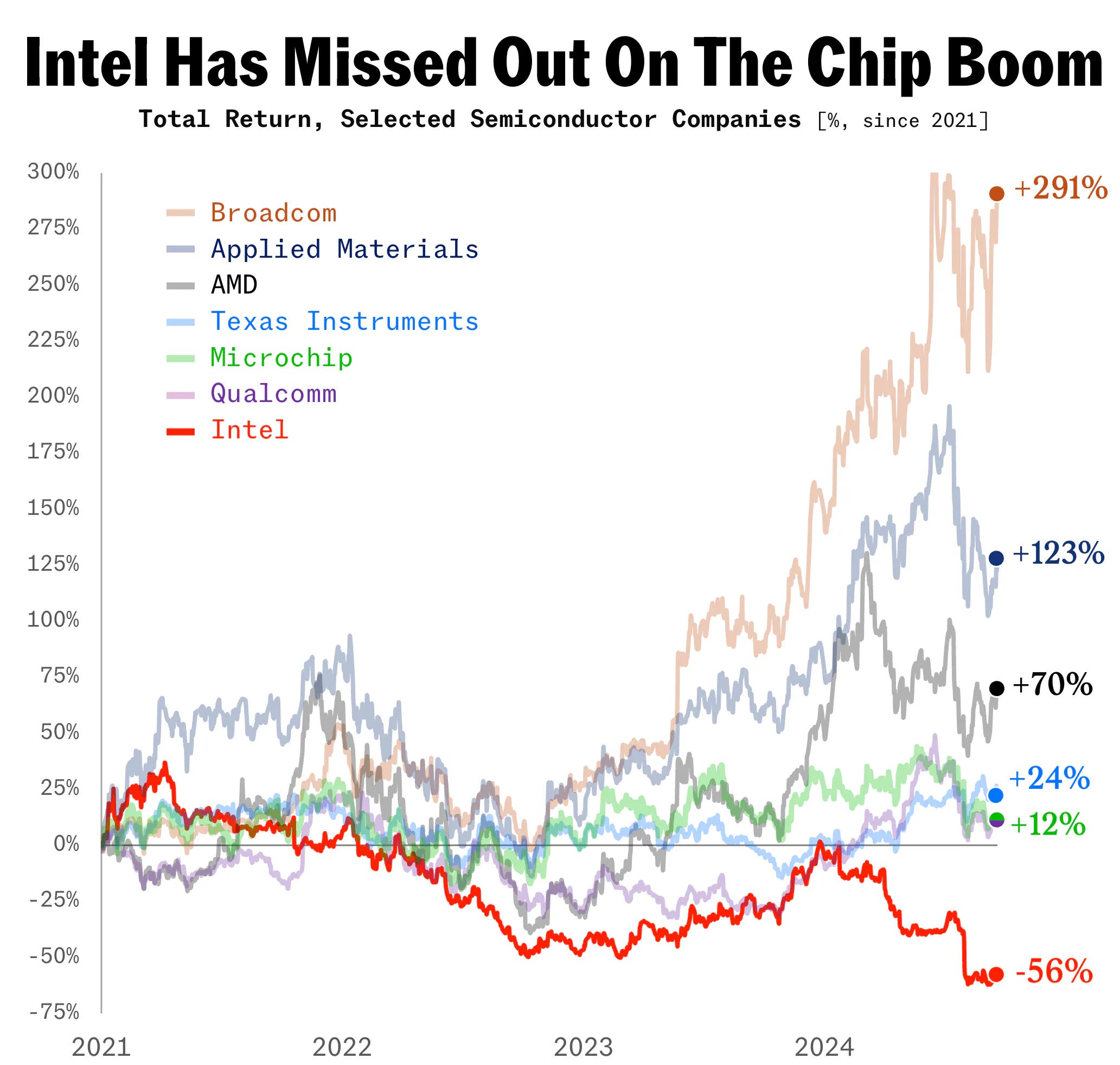
L’attuale CEO Pat Gelsinger sta tentando una complessa operazione di salvataggio che punta a dotare Intel di capacità di manifattura per conto terzi paragonabili a quelle di TSMC, così da alimentare un flusso di cassa con cui nutrire la ricerca avanzata su tecnologie particolarmente futuribili. In pratica Intel continuerebbe a fare entrambe le fasi ma scorporandole e usando una per nutrire l’altra.
È una strategia di difficile attuazione (e che sembra già in difficoltà) che il governo americano seguirà con grande attenzione, visto che su Intel ha scommesso molto denaro del CHIPS and Science Act, oltre che importanti commesse per la difesa.
Gli Stati Uniti considerano del resto Intel uno dei loro asset industriali più strategici nonché un pilastro della loro sicurezza tecnologica. Una crisi terminale dell’azienda – che di recente ha cominciato a perdere quote anche nel mercato delle CPU (vedi grafico sotto) – costituirebbe un durissimo colpo alle ambizioni americane di resilienza nell’industria dei semiconduttori.
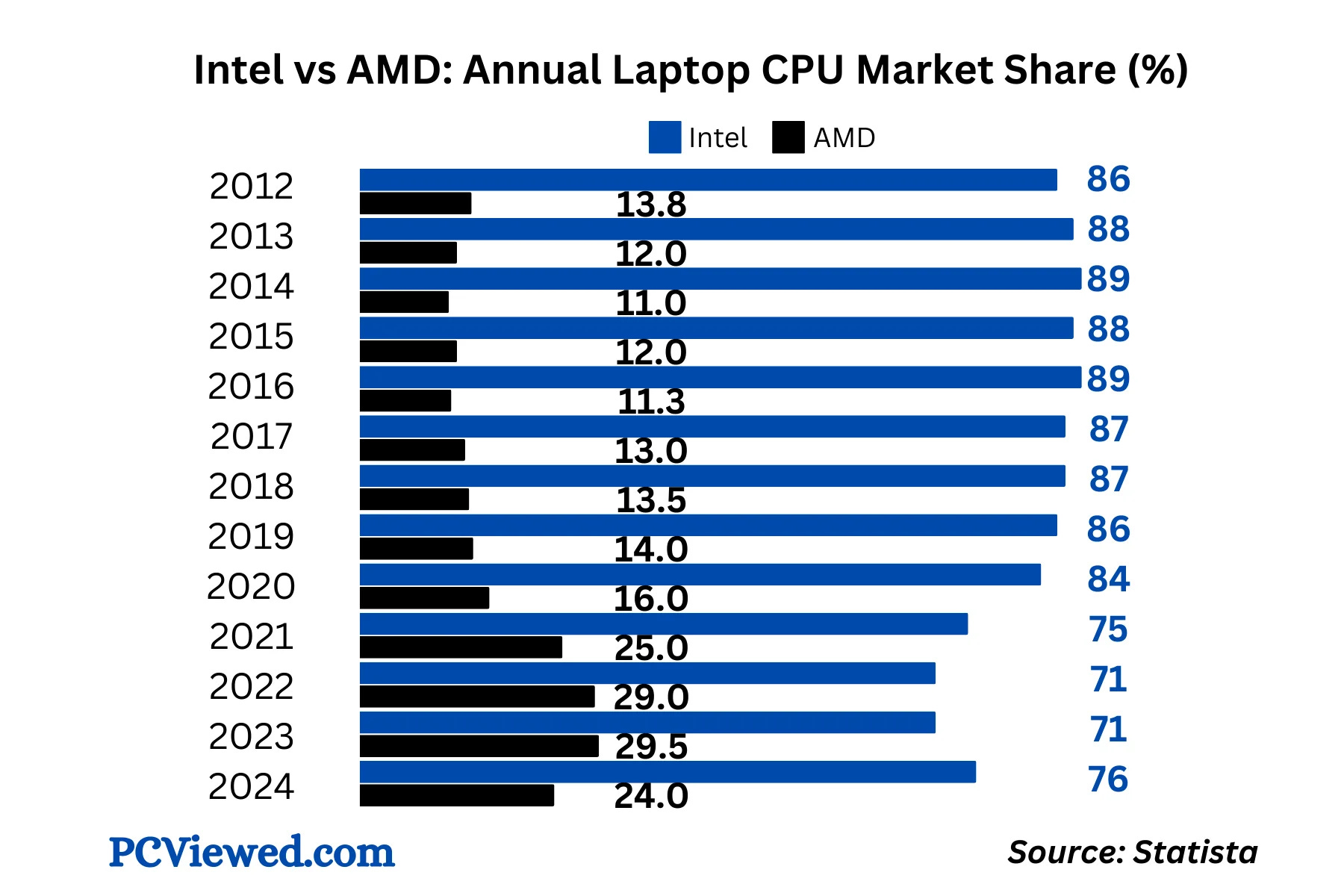
La lezione di Intel
La vicenda di Intel è un esempio emblematico della rapidità con cui si muove il settore dei chip e di come un singolo cambio di paradigma nello stack della computazione possa travolgere persino aziende che hanno scritto la Storia.
Ciò che oggi vale per Intel potrebbe in futuro valere per gli attuali dominatori del settore, soprattutto se commetteranno errori di valutazione grossolani come quello di Ottolini.
Come si è spesso ripetuto negli articoli precedenti, oggi la computazione (AI e non) è dominata da un lato dai soggetti che ne gestiscono l’infrastruttura “macro” – i cosiddetti hyperscaler come Amazon Web Services, Google Cloud e Microsoft Azure – e dall’altro da quelli che meglio padroneggiano la dimensione “micro” dei transistor, come Nvidia e TSMC.
La computazione è intersecata inoltre da tre grandi crisi del suo (e del nostro) tempo: la crisi energetico-ambientale, la crisi politica del mondo multipolare, e la fine della “legge di Moore”, ovvero la crescente difficoltà, per ragioni di natura fisica, di mantenere costante il raddoppio biennale dei transistor a prezzi accettabili.
È possibile, se non certo, che, in un orizzonte medio-lungo, l’intreccio di questi temi trasformerà gli “stati della computazione” in modi tali da renderli quasi irriconoscibili a chi li osserva oggi.
Vale dunque la pena sintetizzare cosa potrebbe accadere in ognuno degli ambiti (micro e macro) in cui agisce la computazione e con quali effetti sul computing stack e sui suoi protagonisti.
Quantum
Come la rivoluzione industriale stimolò lo sviluppo delle infrastrutture energetiche, rendendolo molto più potenti e capillari, in questa fase diverse forze convergenti – l’espandersi dell’AI, i problemi fisici e geopolitici dei chip e quelli energetici degli hyperscaler – promettono di cambiare la natura profonda del computing.
Il calcolo classico, basato sul transistor e sul silicio, è stato finora il modello dominante. Tuttavia, i suoi limiti sono sempre più evidenti e ciò sta spingendo l’industria della computazione a esplorare nuove soluzioni tecnologiche.
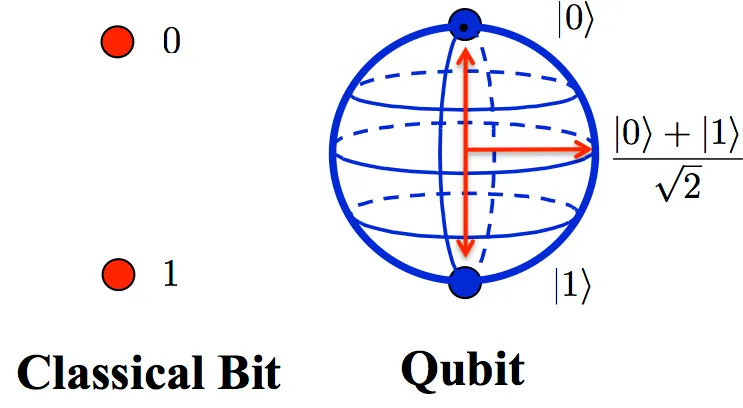
La più estrema, e capace di catturare l’immaginazione , è la computazione quantistica, un paradigma di calcolo che sfrutta i principi della meccanica quantistica, la teoria che descrive il comportamento delle particelle subatomiche.

A differenza dei calcolatori tradizionali, che elaborano informazioni utilizzando bit che possono rappresentare uno solo tra due valori (0 e 1) alla volta, i computer quantistici usano qubit (quantum bit), che possono rappresentare contemporaneamente 0, 1, o una combinazione di entrambi.
Due principi fondamentali rendono la computazione quantistica molto potente: la sovrapposizione e l’entanglement.
Grazie alla sovrapposizione, un qubit può esplorare molte soluzioni contemporaneamente, permettendo ai computer quantistici di affrontare problemi complessi in un tempo molto inferiore rispetto ai computer classici.
In virtù dell’entanglement, i qubit si correlano tra loro così che lo stato di uno dipenda da quello dell’altro, anche a grandi distanze.
Quando i qubit sono entangled, un'operazione su uno di essi influenza immediatamente gli altri, consentendo di rappresentare simultaneamente un numero esponenziali di combinazioni di stati, in pratica una versione iper-potenziata del calcolo parallelo che avviene nei chip GPU con cui oggi si addestrano le AI.
Nonostante i suoi vantaggi, l'entanglement è molto sensibile alle interferenze esterne (il cosiddetto quantum noise), un problema noto come decoerenza quantistica. Questo rende difficile mantenere stati stabili per lunghi periodi di tempo, rappresentando una delle principali sfide nella costruzione e nell’utilizzo di computer quantistici.
Non c’è tuttavia dubbio che un’eventuale maturazione della computazione quantistica rappresenterebbe un evento epocale per tutto l’universo della computazione, al punto che non siamo neppure in grado di pronosticarne la portata (e questo è da intendere sia nel senso che potrebbe eccedere le nostre aspettative, che il contrario).
Ciò che invece già sappiamo è che, date le loro caratteristiche, i computer quantistici avrebbero, per esempio, la capacità di violare in pochi minuti (contro le decine di migliaia di anni necessari a un supercomputer tradizionale) tutte le crittografie su cui si basa la sicurezza delle trasmissioni dati a livello globale.
Per questo le principali potenze del pianeta stanno investendo in modo considerevole nel settore, in modo da assicurarsi il cosiddetto “vantaggio quantistico” rispetto agli avversarsi, e la cosiddetta “resistenza quantistica” nei confronti dei loro potenziali attacchi.
In modo simile a quanto avvenuto nei chip avanzati, gli USA si stanno per esempio muovendo da anni per rallentare lo sviluppo del quantum cinese e hanno di recente aumentato i divieti agli investimenti americani in questo settore in Cina.
Di fronte alla continuità di questa frammentazione geopolitica (che al 99,9% proseguirà sotto Trump e oltre) tra sfera di sviluppo tecnologico americano e sfera cinese, è lecito supporre che il futuro della computazione (quantistica o meno, AI e non solo) rifletterà sempre più profondamente questa spartizione a tutti i livelli, con la formazione di un’infrastruttura caratterizzata da protocolli sempre meno globali e compatibili e sempre più mutualmente esclusivi e con capacità limitate di interazione.
Chip sempre più specializzati
Senza arrivare all’estremo del quantum computing (o di prospettive persino più suggestive come la computazione ottica, neuromorfica o il DNA usato come chip di memoria), l’hardware alla base della computazione – il chip – è destinato per forza di cose a cambiare nei prossimi anni.
Con la “legge di Moore” ormai vicina ai suoi limiti fisici, il futuro dei chip non sarà più dettato solo dalla densità dei transistor, ma piuttosto dalla loro specializzazione e da un’integrazione sempre più stretta con i software.
Chip sempre più specializzati come gli acceleratori per l’AI – NPU, TPU e DPU – sono con ogni probabilità solo i precursori di una nuova era di hardware, in cui ogni elemento dell’ecosistema informatico verrà costruito per una specifica tipologia di calcolo.
Questa frammentazione potrebbe condurre a una sorta di “era post-computazionale” in cui i computer universali, capaci di svolgere qualsiasi compito, lasceranno il posto a un insieme di dispositivi ottimizzati per applicazioni individuali.
Il risultato sarà un panorama frammentato, in cui ogni settore industriale potrebbe avere un proprio tipo di chip specializzato: automotive, sanità, telecomunicazioni e difesa etc, ognuno di questi ambiti richiederà hardware personalizzati e interamente progettati in funzione delle loro specifiche esigenze.
Per tenere sotto controllo i costi di produzione di oggetti sempre meno “universali”, una buona strategia potrebbe essere il ricorso ai chiplet, ovvero un nuovo approccio, in stile Lego, alla produzione di semiconduttori, componibili in diverse configurazioni più grandi, da specializzare a seconda delle necessità.
L’azienda che per prima ha esplorato questo settore, Siliconbox di Singapore, ha da poco confermato un investimento da 3,2 miliardi per un impianto di produzione in Italia, nel novarese.
Il ruolo dell’AI e dell’edge computing
L’AI non è solo un prodotto dell’infrastruttura della computazione ma un suo componente ormai sempre più fondamentale.
Se oggi le reti neurali e gli algoritmi di deep learning vengono addestrati su hardware specifici, come le stra-citate GPU, nei prossimi anni queste tecnologie evolveranno per integrare AI che ottimizzino in modo auto-evolutivo le proprie risorse hardware.
I sistemi AI potrebbero insomma non solo interagire con i dati per generare risposte, ma anche per migliorare le proprie stesse architetture e l’uso delle loro risorse, con notevoli effetti di tipo economico, qualitativo ed energetico.
In uno scenario del genere, l’infrastruttura della computazione potrebbe trovarsi a dover affrontare dinamiche molto diverse da quelle attuali.
Produttori di chip e hyperscaler che oggi sembrano dotati di un vantaggio così profondo da non essere più recuperabile si troverebbero a doversi guardare le spalle da competitor con forse meno potenza a disposizione ma con migliori AI per ottimizzarne l’uso (è tuttavia più probabile che i vantaggi si “compongano” e i soggetti con le maggiori risorse siano anche quelli con le migliori AI a disposizione).
Un’altra profonda evoluzione delle dinamiche tecnologiche ed economiche dell’infrastruttura della computazione verrà dalla crescente diffusione dell’edge computing.
Paragonabile metaforicamente a una sorta di filosofia “chilometro 0” applicata alla computazione, l’edge computing è un modello di calcolo distribuito nel quale la computazione avviene il più vicino possibile a dove i dati da elaborare sono stati generati.
Spostando il calcolo più vicino ai dati di origine, si riduce la necessità di trasferire e immagazzinare grandi volumi di informazioni in singoli enormi data center. Ciò porta vantaggi in termini di tempi di elaborazione (particolarmente critici per applicazioni AI come le automobili a guida autonoma e i robot industriali), di volume complessivo del traffico dei dati e di consumi energetici a essi connessi.
Se si dimostrerà più sostenibile, conveniente e scalabile, la diffusione dell’edge computing potrebbe segnare inoltre la fine del modello dominante dei data center centralizzati a favore di infrastrutture più piccole e maggiormente distribuite.
In un simile scenario, persino i colossi oggi inscalfibili del cloud computing e gli hyperscaler dovrebbero evolversi, pena il rischio di finire nella situazione in cui si trova oggi Intel.

Se siete nuovi da queste parti, io mi chiamo Cesare Alemanni. Mi interesso di questioni all’intersezione tra economia e geopolitica, tecnologia e cultura. Per Luiss University Press ho pubblicato La signora delle merci. Dalle caravelle ad Amazon, come la logistica governa il mondo (2023) e Il re invisibile. Storia, economia e sconfinato potere del microchip(2024).

: